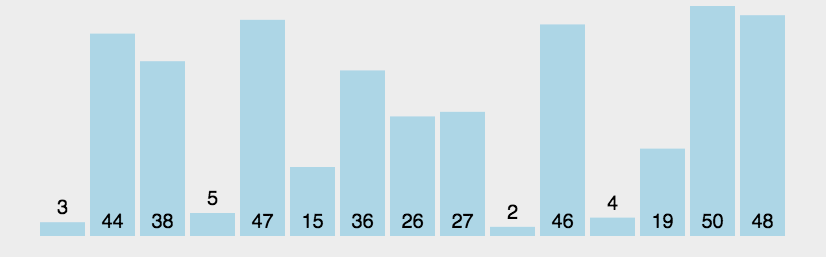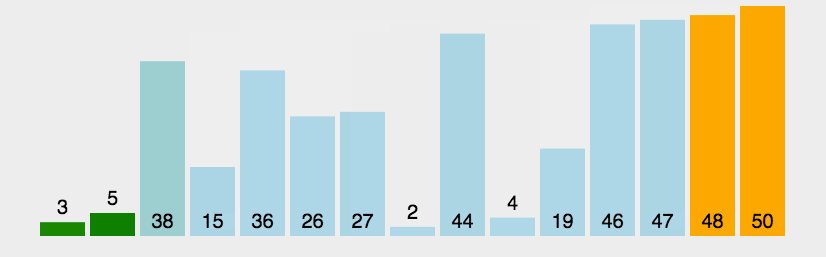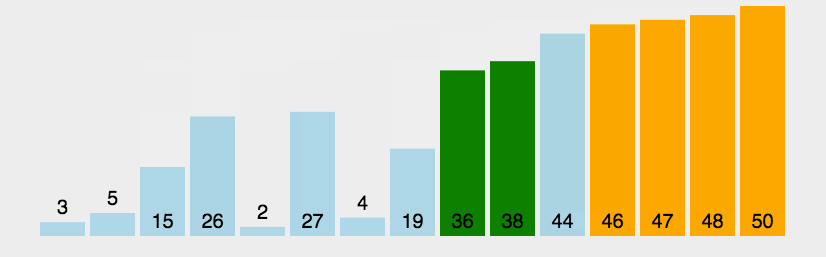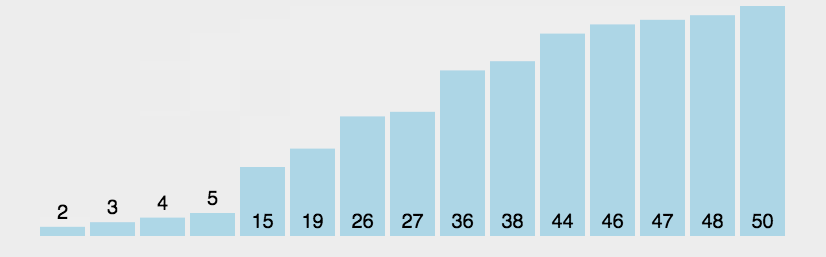内容概要:
算法初识 算法的度量
时间频度 基本介绍 时间频度: 一个算法花费的时间与算法中语句的执行次数成正比例 语句频度或时间频度 T(n) 。
时间频度举例 比如 计算 1-100 所有数字之和 两种算法
1 2 3 4 5 6 7 8 9 int total = 0 ;int end = 100 ;for (int i = 1 ; i < end; i++){ total += i; } total = (1 + end) * end / 2 ;
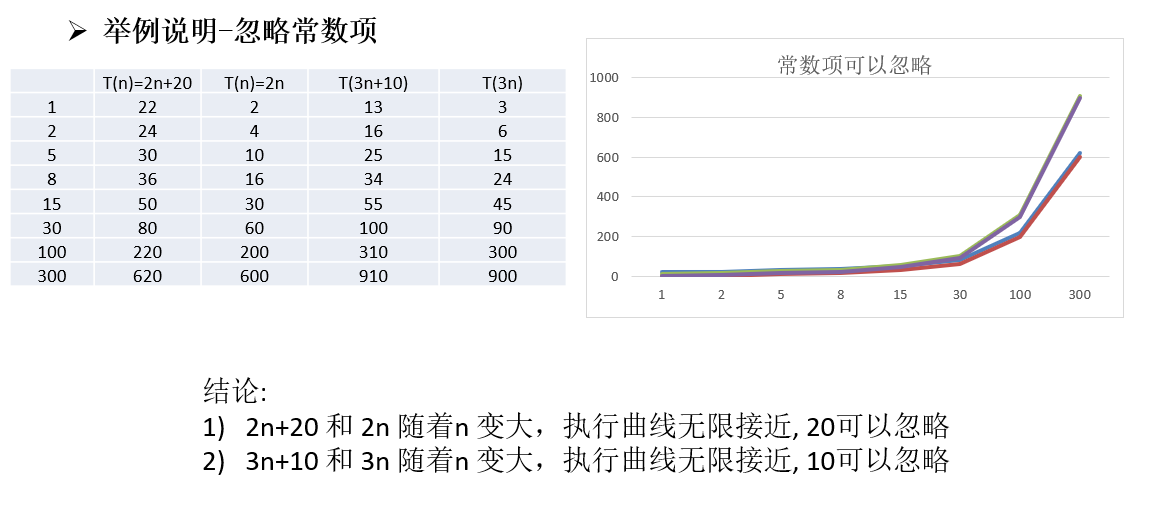
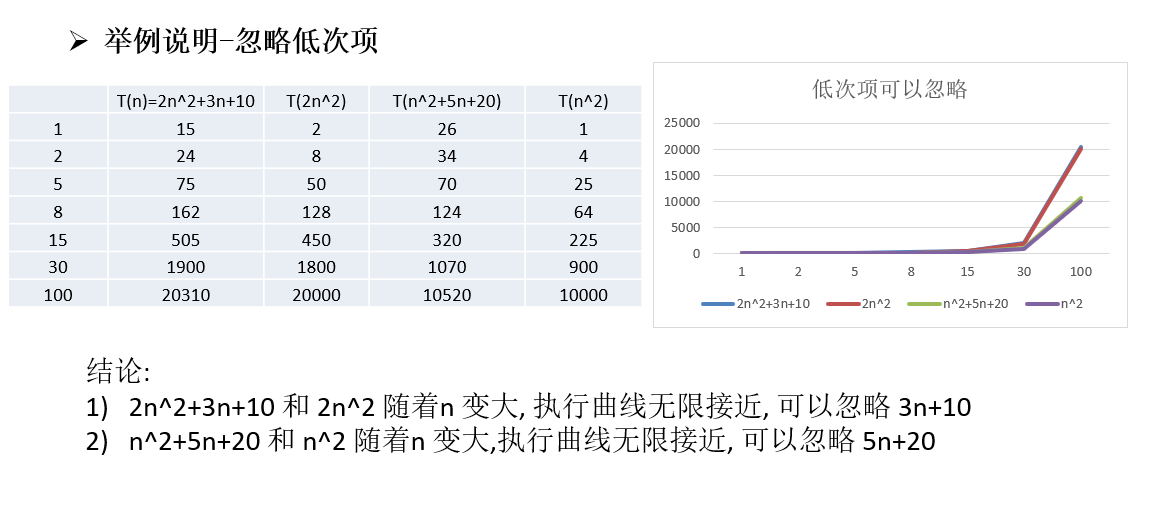
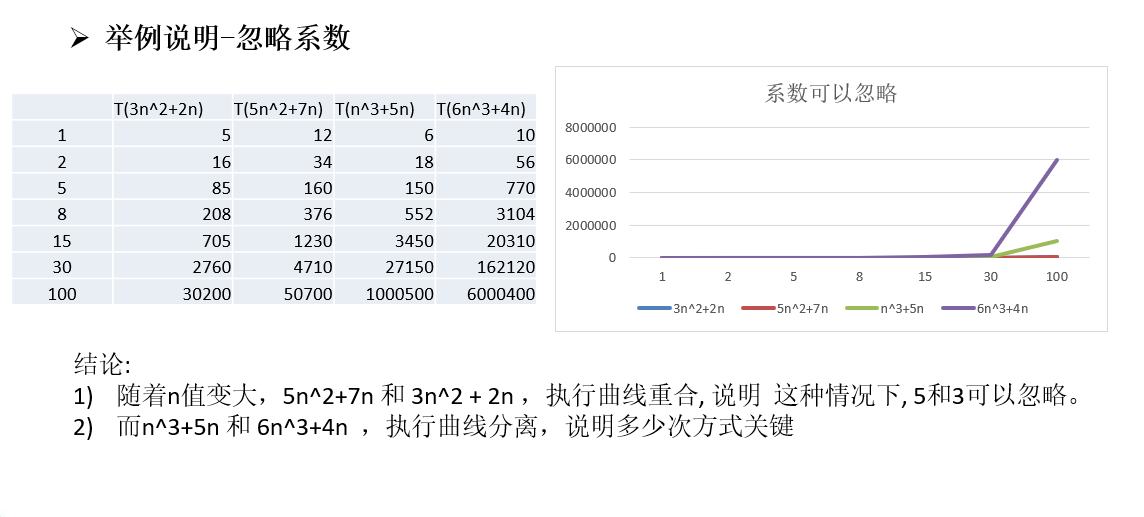
注意事项 第一: 常数项能够被忽略
第二: 低次项能够被忽略
第三: 系数能够被忽略
时间复杂度 基本概念 一般情况下,算法中的基本操作 语句的重复执行次数是问题规模 n 的某个函数 T(n) T(n) / f(n) 的极限值为不等于零的常数,则称 f(n) 是 T(n) 的同数量级函数。记作 T(n) = O(f(n)) ,称 O(f(n)) 为算法的 渐进时间复杂度 时间复杂度 。
TIPS:
T(n) 不同,但时间复杂度可能相同 T(n) = n² + 7n + 6 与 T(n) = 3n² + 2n + 2
计算方法
用常数 1 代替运行时间中的所有加法常数: T(n) = 3n²+7n+6 => T(n) = 3n²+7n+1修改后的运行次数函数中,只保留最高阶项: T(n)=3n²+7n+1 => T(n) = 3n²去除最高阶项的系数: T(n) = 3n² => T(n) = n² => O(n²)
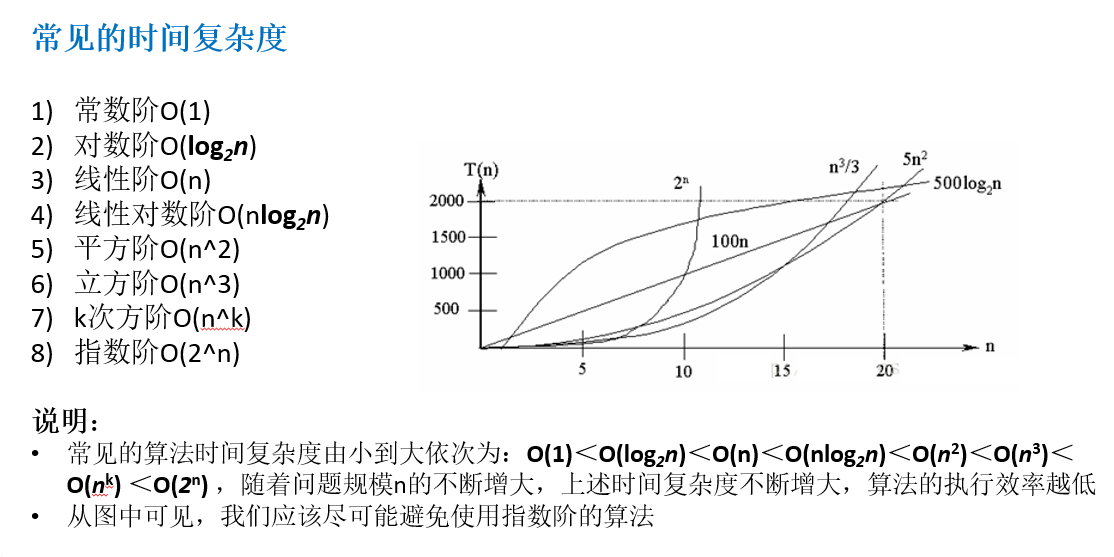
常见的时间复杂度 常见的时间复杂度
常数阶 举例:
对数阶 举例:
线性阶 举例:
线性对数阶 举例:
平方阶 举例:
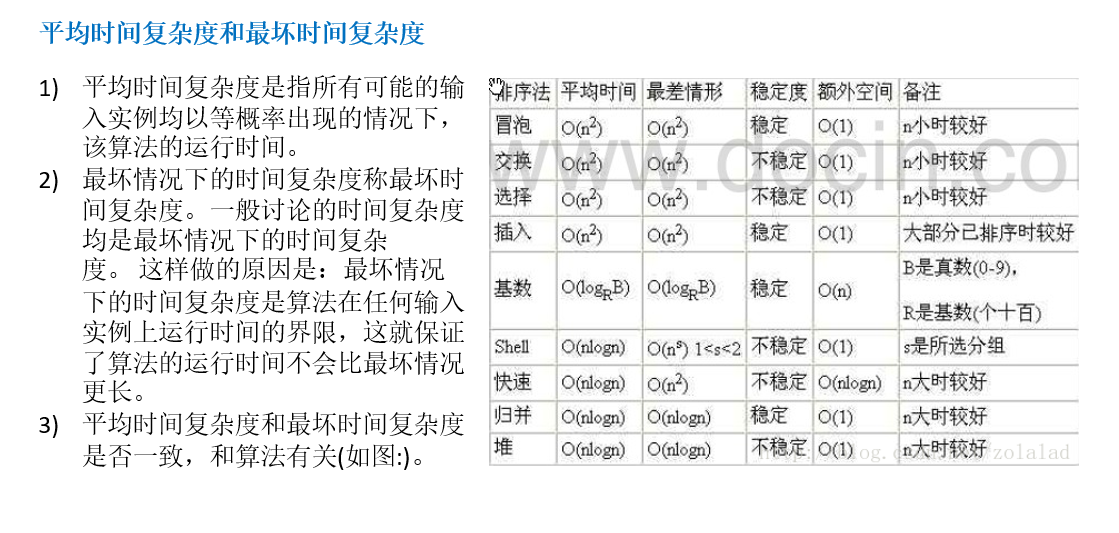
平均 / 最坏时间复杂度 平均时间复杂度 和 最坏时间复杂度 的解释都在图中:
空间复杂度
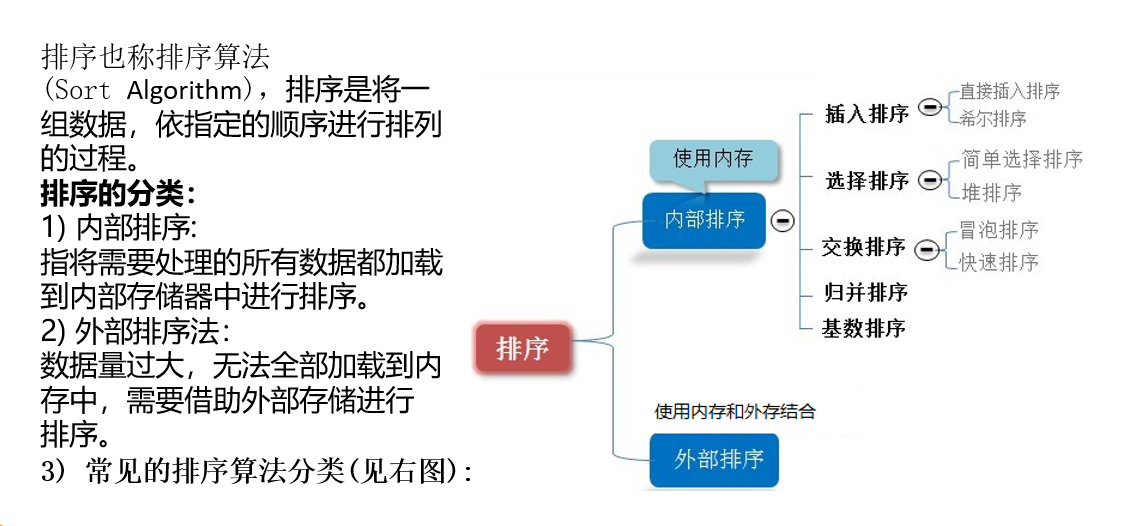
排序算法 先看一张图,了解 排序算法
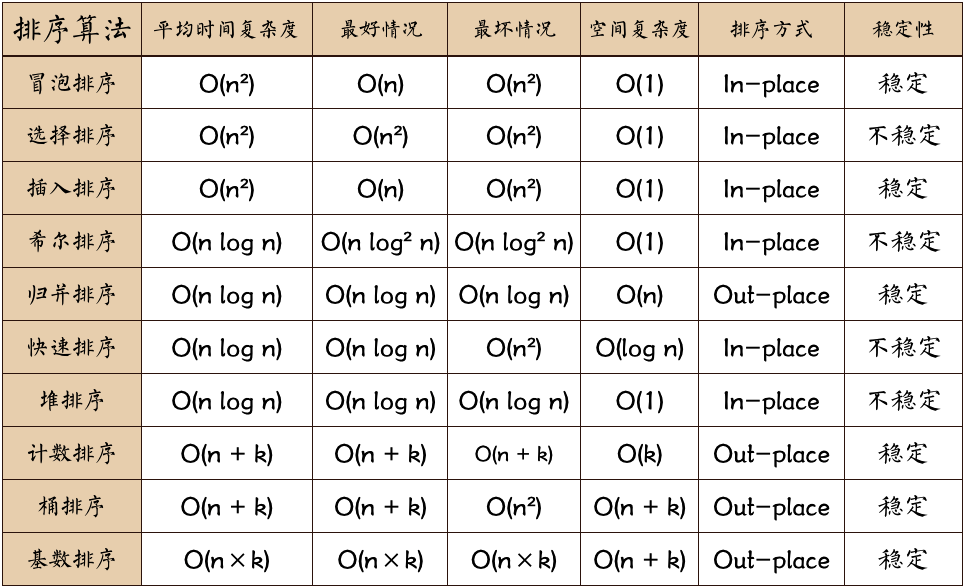
以下是 十大排序算法 ,每种算法都分析了 平均时间复杂度 、最好情况 、最坏情况 、空间复杂度 、排序方式和稳定性 。详情参考下图:
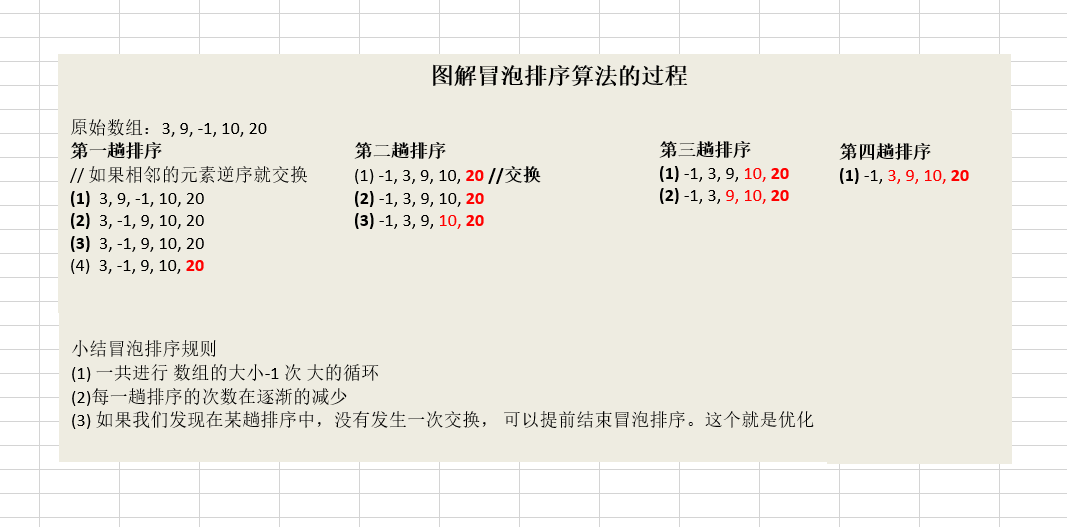
冒泡排序 基本介绍 在一个数组中,相邻两个元素进行对比,小的放在前,大的放在后,第一轮比完就找到了最大的数并且放在最后。依此类推,直到排序完成。
冒泡排序图解 静态图解:
动态图解:
代码实现标准版 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Main public static void bubbleSort (int [] arr) if (arr == null || arr.length < 2 ) { return ; } for (int e = arr.length - 1 ; e > 0 ; e--) { for (int i = 0 ; i < e; i++) { if (arr[i] > arr[i + 1 ]) { swap(arr, i, i + 1 ); } } } } public static void swap (int [] arr, int i, int j) arr[i] = arr[i] ^ arr[j]; arr[j] = arr[i] ^ arr[j]; arr[i] = arr[i] ^ arr[j]; } }
代码实现升级版 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static void bubbleSort (int [] arr) boolean flag = false ; if (arr == null || arr.length < 2 ) { return ; } for (int i = arr.length - 1 ; i > 0 ; i--) { for (int j = 0 ; j < i; j++) { if (arr[j] > arr[j + 1 ]) { flag = true ; arr[j] = arr[j] ^ arr[j + 1 ]; arr[j + 1 ] = arr[j] ^ arr[j + 1 ]; arr[j] = arr[j] ^ arr[j + 1 ]; } } System.out.println("第" + (arr.length - i) + "趟排序" ); System.out.println(Arrays.toString(arr)); if (flag){ flag = false ; } else { break ; } } }
算法测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public static void main (String[] args) int [] arr = new int [100000 ]; for (int i = 0 ; i < arr.length; i++) { arr[i] = (int )(Math.random() * 1000 + 1 ); } long start = System.currentTimeMillis(); bubbleSort(arr); long end = System.currentTimeMillis(); System.out.println("排序 10 万个数据需要 " + (end - start) / 1000 + " 秒!" ); } public static void bubbleSort (int [] arr) boolean flag = false ; if (arr == null || arr.length < 2 ) { return ; } for (int i = arr.length - 1 ; i > 0 ; i--) { for (int j = 0 ; j < i; j++) { if (arr[j] > arr[j + 1 ]) { flag = true ; arr[j] = arr[j] ^ arr[j + 1 ]; arr[j + 1 ] = arr[j] ^ arr[j + 1 ]; arr[j] = arr[j] ^ arr[j + 1 ]; } } if (flag){ flag = false ; } else { break ; } } }
冒泡排序总结:
选择排序 基本介绍 选择排序就是在未排序的数组中,第一个元素和它以后的每一个元素进行比较,若第一个元素大于第 i 个元素,那么两元素交换位置。然后第一个元素继续和第 i + 1 个元素比较,直到结束。第一次比较后的结果找到了最小的数并放在数组第一个位置。后面从第二个数开始和它以后的数比较,以此类推,直到排序完成。
选择排序图解 代码实现标准版 1 2 3 4 5 6 7 8 9 10 11 12 public static void selectSort (int [] arr) for (int i = 0 ; i < arr.length - 1 ; i++) { for (int j = i + 1 ; j < arr.length; j++) { if (arr[i] > arr[j]) { int temp; temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } } } }
代码测试版 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import java.text.SimpleDateFormat;import java.util.Arrays;import java.util.Date;public class SelectSort public static void main (String[] args) int [] arr = new int [80000 ]; for (int i = 0 ; i < 80000 ; i++) { arr[i] = (int ) (Math.random() * 8000000 ); } System.out.println("排序前" ); Date data1 = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss" ); String date1Str = simpleDateFormat.format(data1); System.out.println("排序前的时间是=" + date1Str); selectSort(arr); Date data2 = new Date(); String date2Str = simpleDateFormat.format(data2); System.out.println("排序前的时间是=" + date2Str); } public static void selectSort (int [] arr) for (int i = 0 ; i < arr.length - 1 ; i++) { int minIndex = i; int min = arr[i]; for (int j = i + 1 ; j < arr.length; j++) { if (min > arr[j]) { min = arr[j]; minIndex = j; } } if (minIndex != i) { arr[minIndex] = arr[i]; arr[i] = min; } } } }
总结:
插入排序 基本介绍
插入排序图解
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void insertSort (int [] arr) for (int i = 1 ; i < arr.length; i++) { int insertValue = arr[i]; int insertIndex = i - 1 ; while (insertIndex >= 0 && insertValue < arr[insertIndex]){ arr[insertIndex + 1 ] = arr[insertIndex]; insertIndex--; } arr[insertIndex + 1 ] = insertValue; } }
总结:
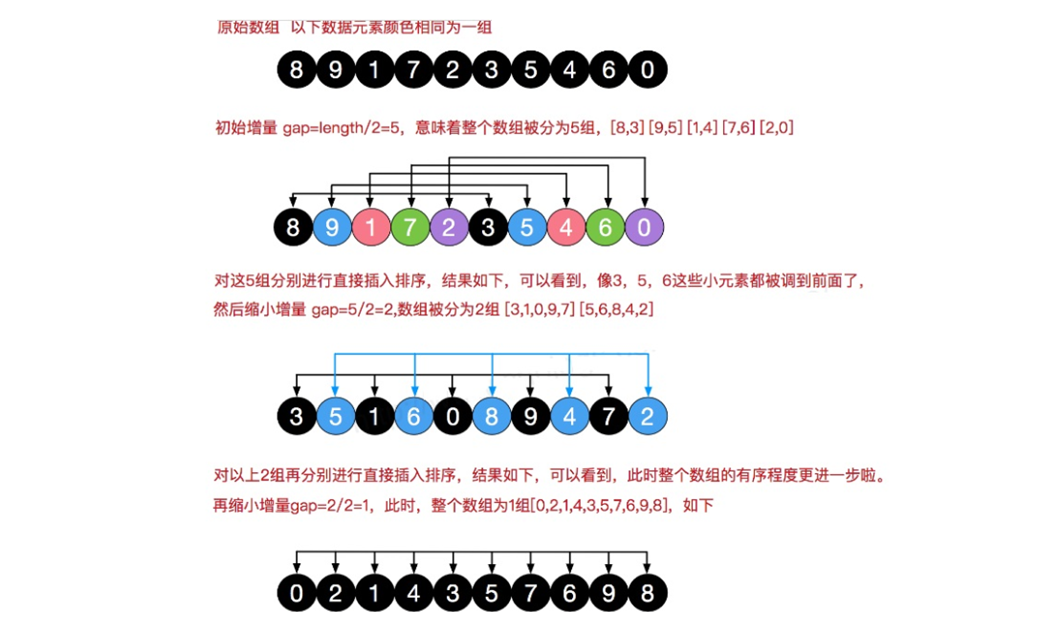
希尔排序 问题引入
基本介绍
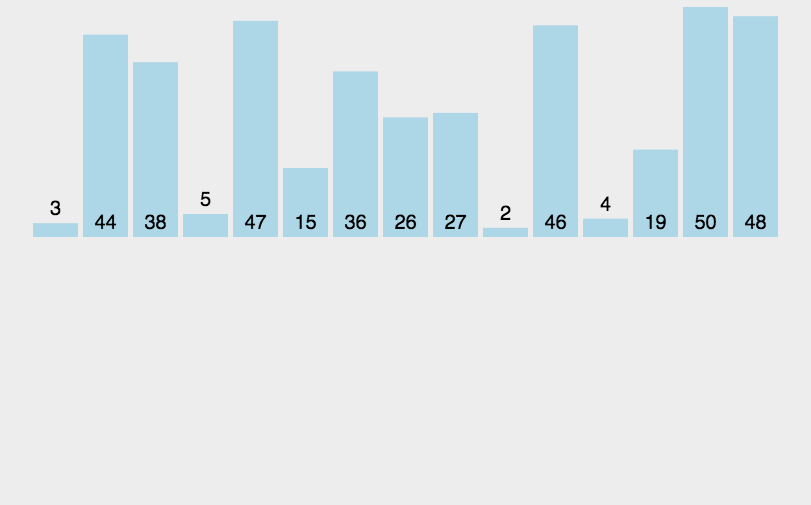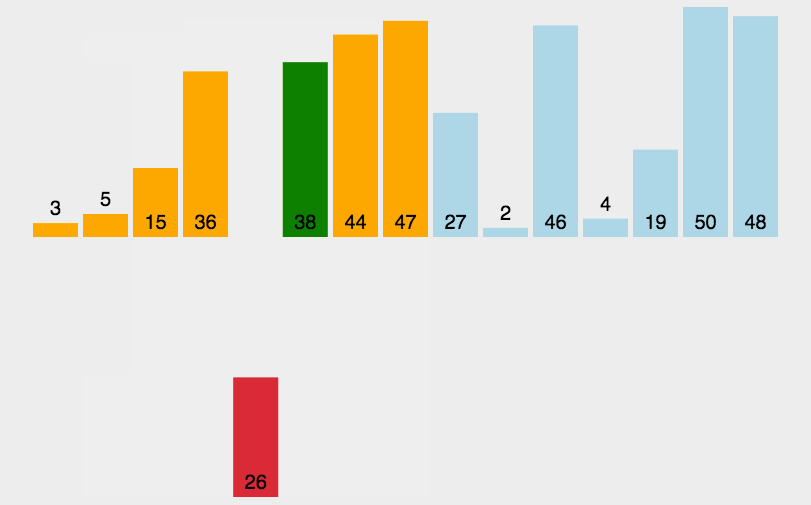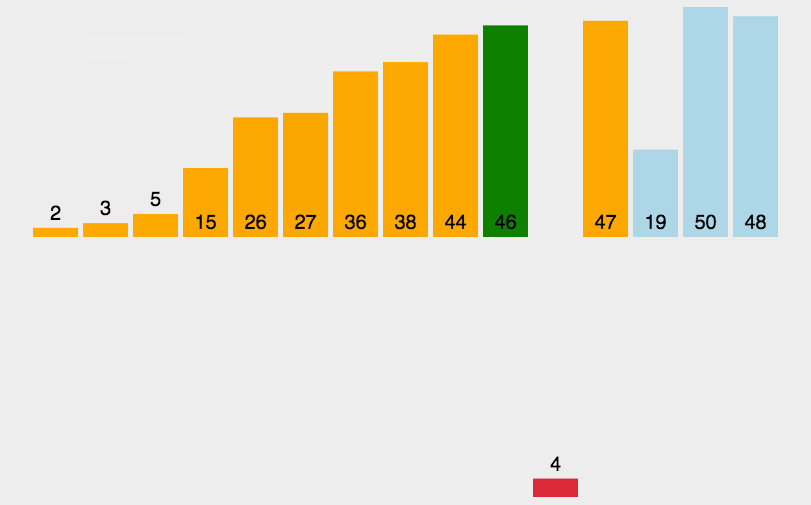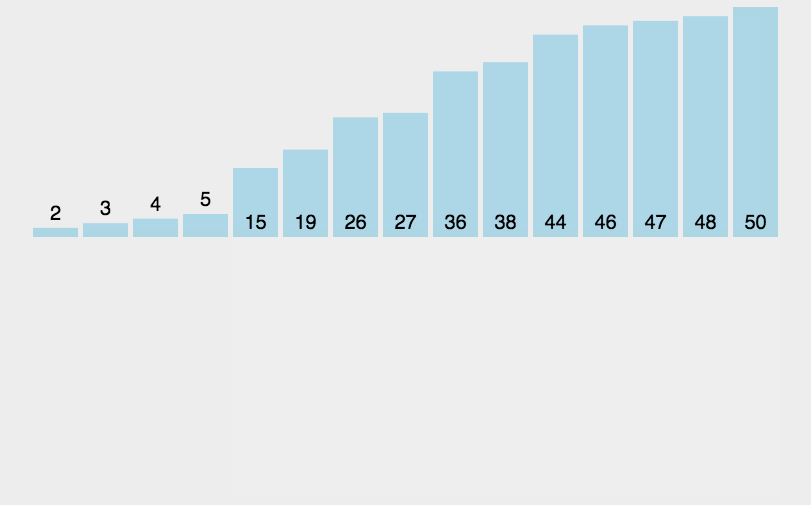
希尔排序图解 静态图解:
动态图解:
代码实现 采用 交换法 实现希尔排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void shellSort (int [] arr) int temp; for (int gap = arr.length / 2 ; gap > 0 ; gap /= 2 ) { for (int i = gap; i < arr.length; i++){ for (int j = i - gap; j >= 0 ; j -= gap){ if (arr[j] > arr[j + gap]){ temp = arr[j]; arr[j] = arr[j + gap]; arr[j + gap] = temp; } } } } }
采用 移动法 实现希尔排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void shellSort2 (int [] arr) for (int gap = arr.length / 2 ; gap > 0 ; gap /= 2 ) { for (int i = gap; i < arr.length; i++) { int j = i; int temp = arr[j]; if (arr[j] < arr[j - gap]){ while (j - gap >= 0 && temp < arr[j - gap]) { arr[j] = arr[j - gap]; j -= gap; } arr[j] = temp; } } } }
总结一下:
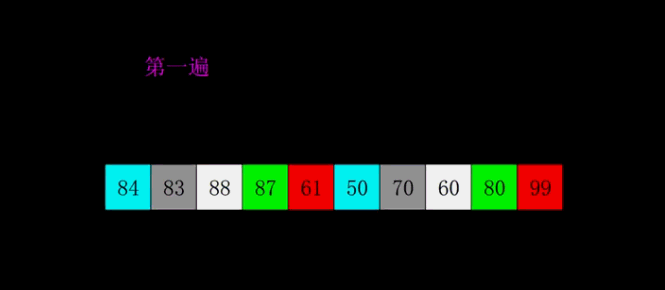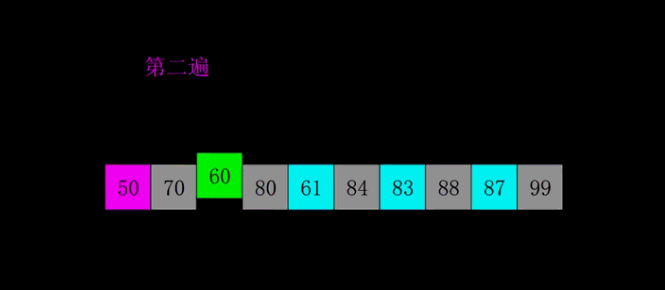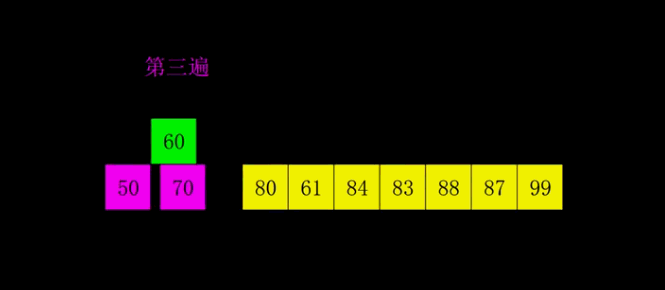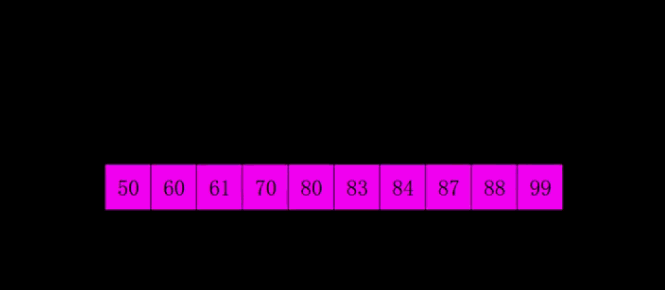
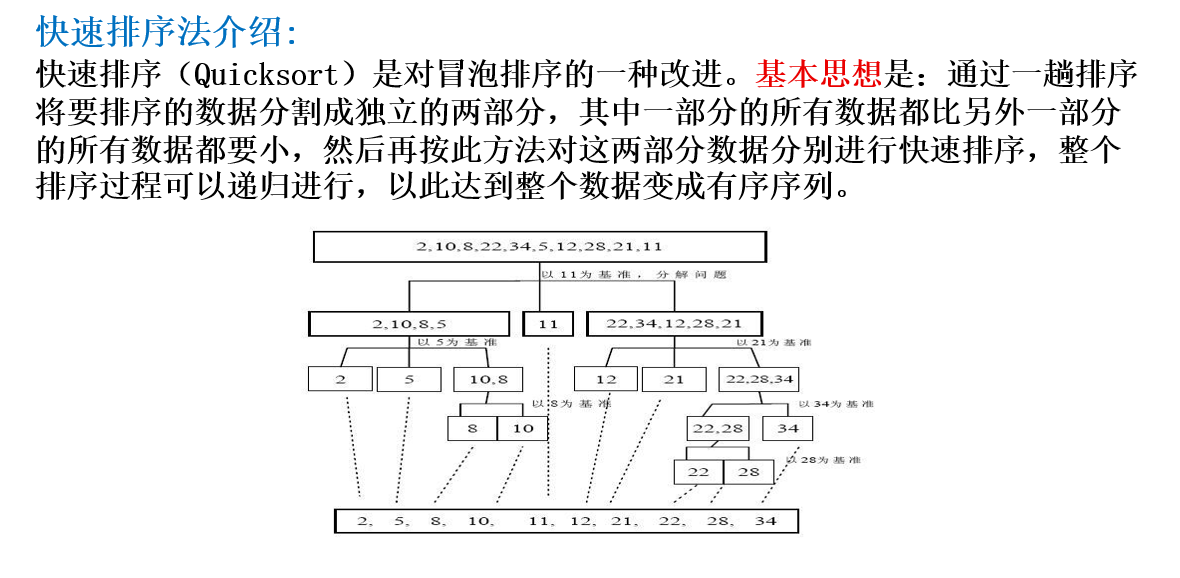
快速排序 基本介绍
快速排序图解
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public static void quickSort (int [] arr, int left, int right) int lt = left; int rt = right; int pivot = arr[(left + right) / 2 ]; int temp; while (lt < rt){ while (arr[lt] < pivot){ lt += 1 ; } while (arr[rt] > pivot){ rt -= 1 ; } if (lt >= rt){ break ; } temp = arr[lt]; arr[lt] = arr[rt]; arr[rt] = temp; if (arr[lt] == pivot){ rt--; } if (arr[rt] == pivot){ lt++; } } if (lt == rt){ lt++; rt--; } if (left < rt){ quickSort(arr, left, rt); } if (right > lt){ quickSort(arr, lt, right); } }
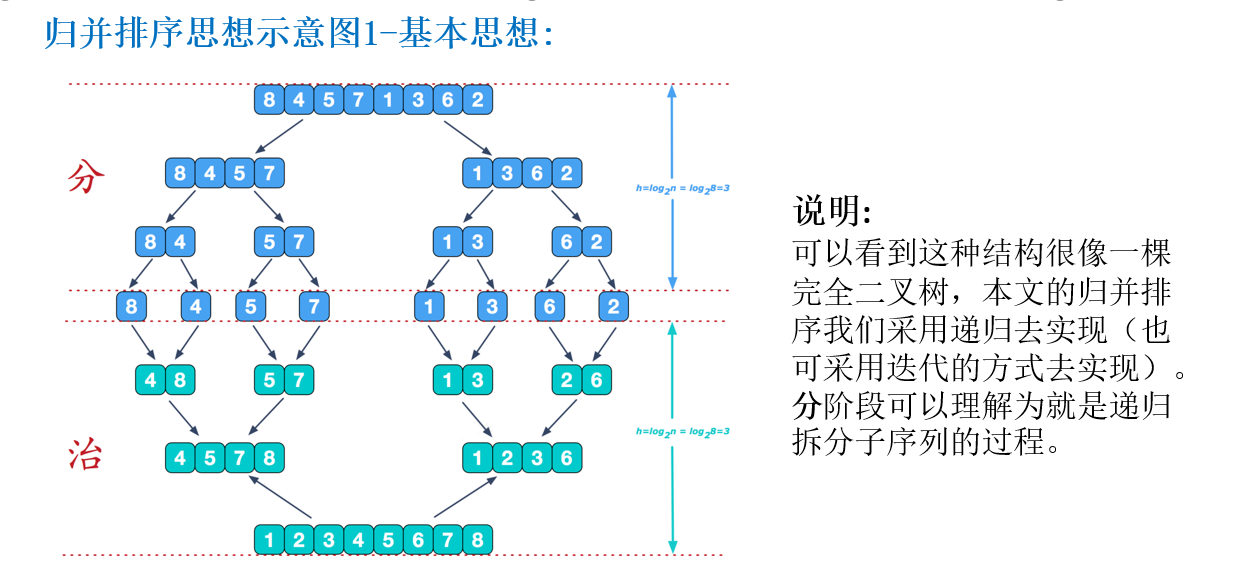
归并排序 基本介绍 归并排序(MERGE-SORT) 是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分( divide )成一些小的问题然后递归求解,而治( conquer )的阶段则将分的阶段得到的各答案”修补”在一起,即分而治之)。
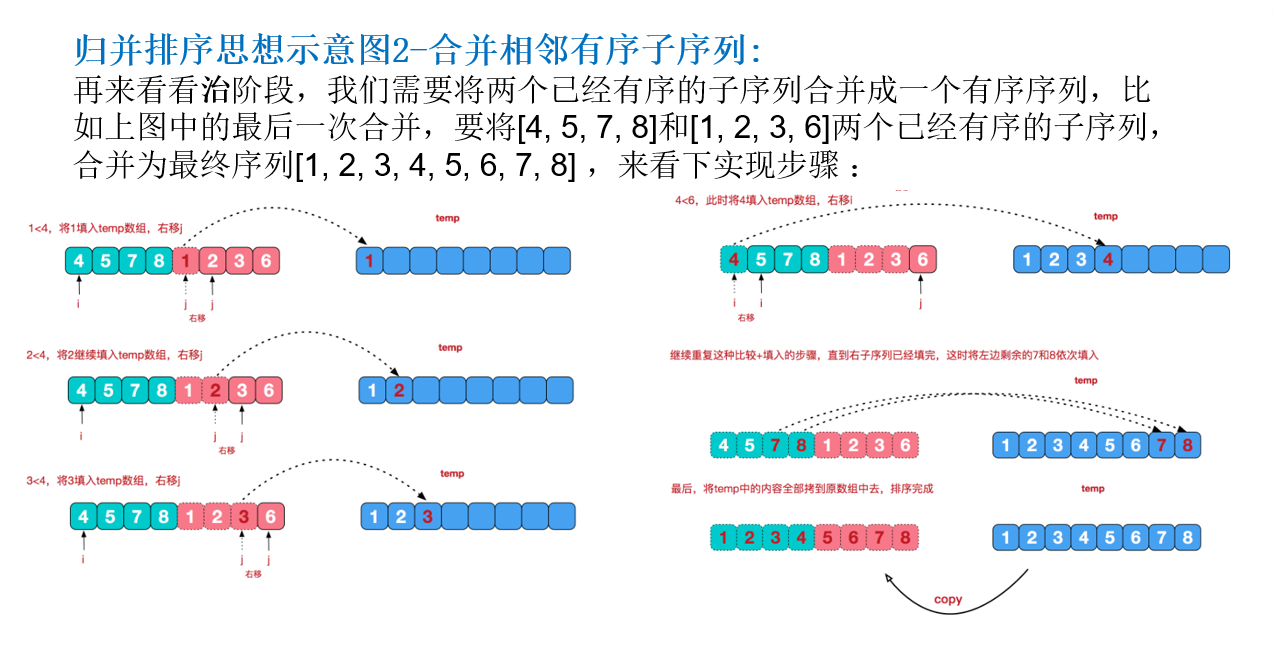
归并排序图解 静态图解:
动态图解:
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public static void main (String[] args) int [] arr = new int [30 ]; int [] temp = new int [arr.length]; for (int i = 0 ; i < 30 ; i++) { arr[i] = (int ) (Math.random() * 70 + 10 ); } mergeSort(arr, 0 , arr.length - 1 , temp); System.out.println(Arrays.toString(arr)); } public static void mergeSort (int [] arr, int left, int right, int [] temp) if (left < right) { int mid = (left + right) / 2 ; mergeSort(arr, left, mid, temp); mergeSort(arr, mid + 1 , right, temp); mergeSort(arr, left, mid, right, temp); } } public static void mergeSort (int [] arr, int left, int mid, int right, int [] temp) int i = left; int j = mid + 1 ; int t = 0 ; while (i <= mid && j <= right) { if (arr[i] <= arr[j]) { temp[t] = arr[i]; t++; i++; } else { temp[t] = arr[j]; t++; j++; } } while (i <= mid) { temp[t] = arr[i]; t++; i++; } while (j <= right) { temp[t] = arr[j]; t++; j++; } t = 0 ; int tempLeft = left; while (tempLeft <= right) { arr[tempLeft] = temp[t]; t++; tempLeft++; } }
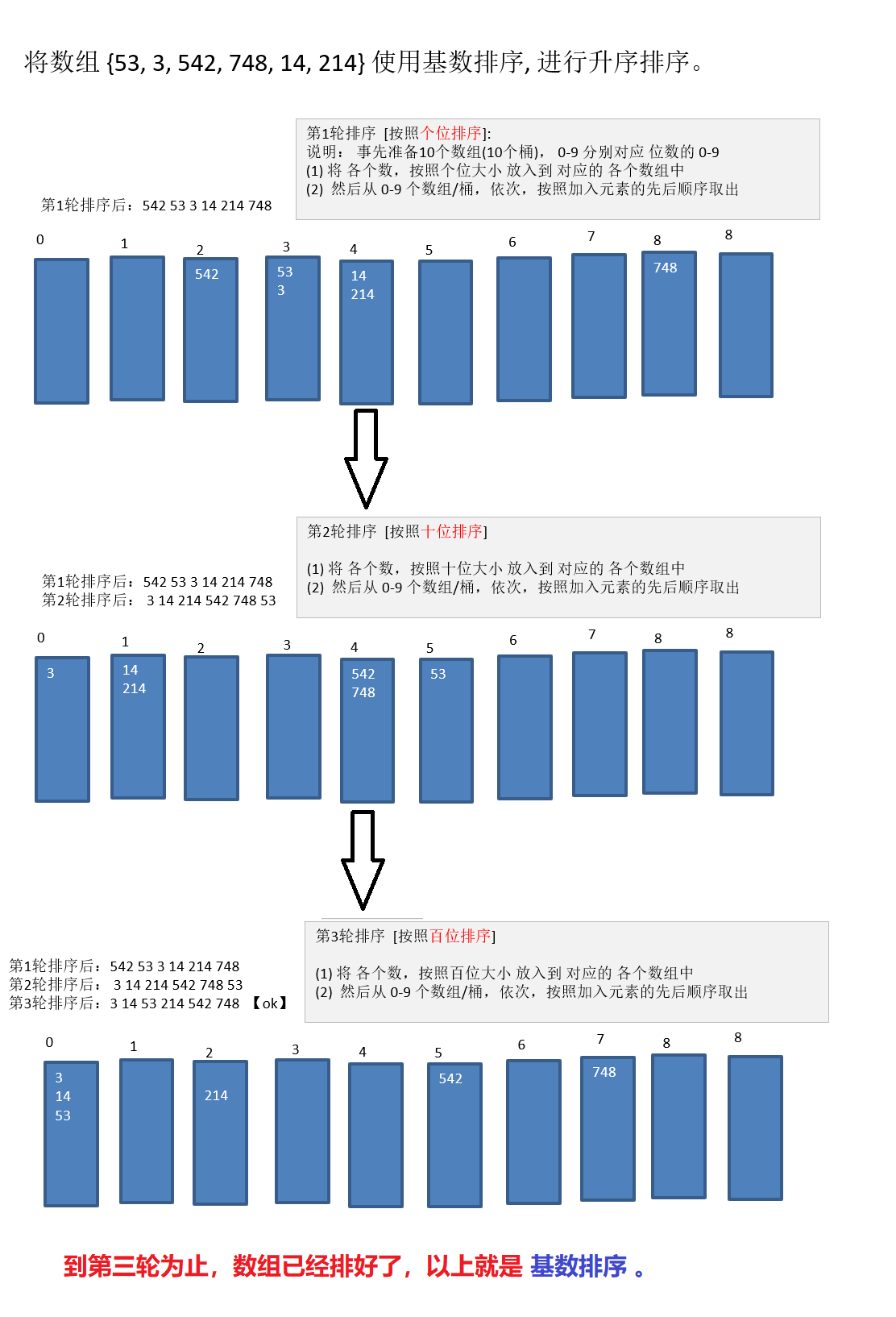
基数排序 基本介绍
基数排序图解 静态图解:
动态图解:
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public static void redixSort (int [] arr) int max = arr[0 ]; for (int i = 1 ; i < arr.length; i++) { if (arr[i] > max) { max = arr[i]; } } int maxLength = (max + "" ).length(); int [][] bucket = new int [10 ][arr.length]; int [] counts = new int [10 ]; for (int i = 0 , n = 1 ; i < maxLength; i++, n *= 10 ) { for (int j = 0 ; j < arr.length; j++) { int element = arr[j] / n % 10 ; bucket[element][counts[element]] = arr[j]; counts[element]++; } int index = 0 ; for (int k = 0 ; k < bucket.length; k++) { if (counts[k] != 0 ) { for (int m = 0 ; m < counts[k]; m++) { arr[index++] = bucket[k][m]; } } counts[k] = 0 ; } } }
基数排序说明
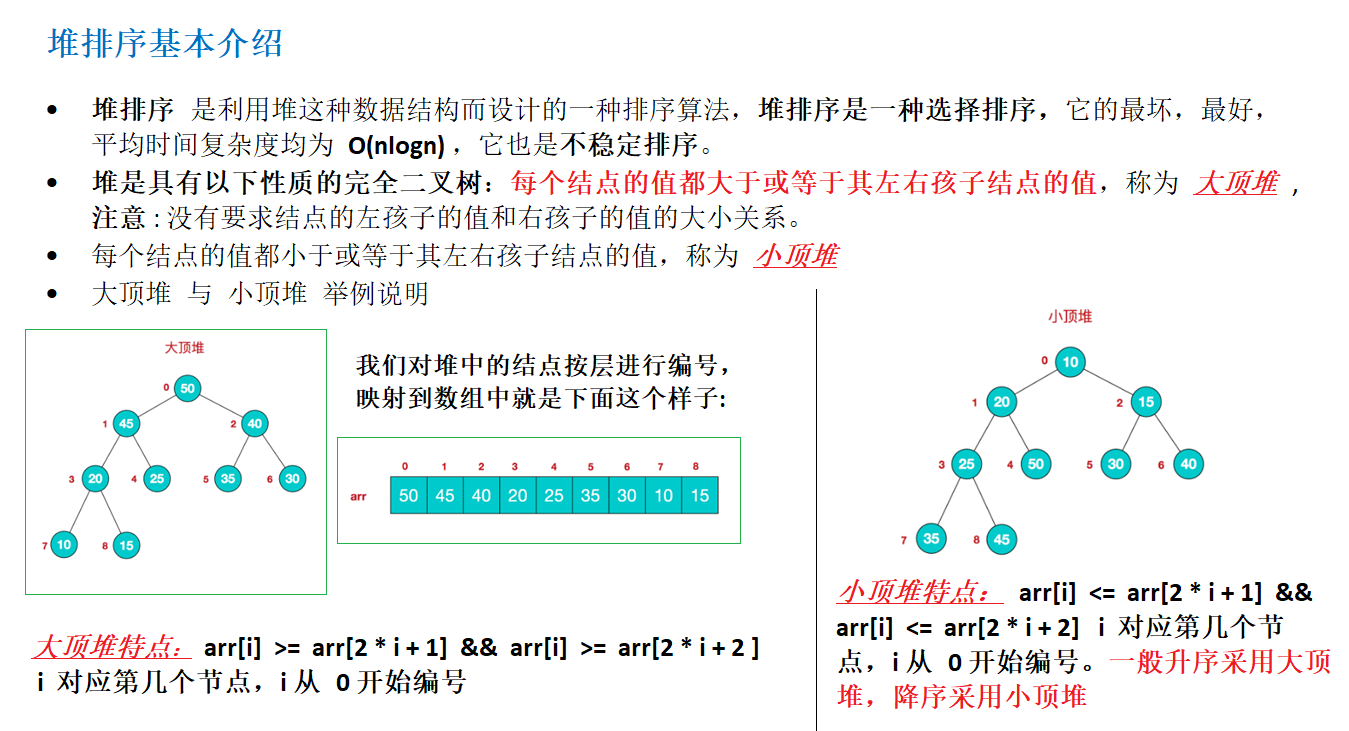
堆排序 基本介绍 堆排序 是一种选择排序 堆 这种数据结构而设计的一种排序算法。具体介绍如下图:
堆排序图解
代码实现 堆排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 public class HeapSort public static void main (String[] args) int [] arr = {4 , 6 , 8 , 5 , 9 }; heapSort(arr); } public static void heapSort (int [] arr) int temp = 0 ; System.out.println("堆排序!" ); for (int i = arr.length / 2 - 1 ; i >= 0 ; i--) { adjustHeap(arr, i, arr.length); } for (int j = arr.length - 1 ; j > 0 ; j--) { temp = arr[j]; arr[j] = arr[0 ]; arr[0 ] = temp; adjustHeap(arr, 0 , j); } System.out.println(Arrays.toString(arr)); } public static void adjustHeap (int [] arr, int i, int length) int temp = arr[i]; for (int k = 2 * i + 1 ; k < length; k = k * 2 + 1 ) { if ((k + 1 ) < length && arr[k] < arr[k + 1 ]) { k++; } if (arr[k] > temp) { arr[i] = arr[k]; i = k; } else { break ; } } arr[i] = temp; } }
排序算法性能测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 public static void main (String[] args) int [] arr = new int [80000 ]; int [] temp = new int [arr.length]; for (int i = 0 ; i < 80000 ; i++) { arr[i] = (int ) (Math.random() * 8000 + 1 ); } long start = System.currentTimeMillis(); long end = System.currentTimeMillis(); System.out.println("排序 8万数据 需要的时间 = " + (end - start) / 1000 + " 秒 " + (end - start) % 1000 + " 毫秒" ); } public static void bubbleSort (int [] arr) for (int i = 0 ; i < arr.length - 1 ; i++) { for (int j = 0 ; j < arr.length - i - 1 ; j++) { if (arr[j] > arr[j + 1 ]) { int temp; temp = arr[j]; arr[j] = arr[j + 1 ]; arr[j + 1 ] = temp; } } } } public static void selectSort (int [] arr) for (int i = 0 ; i < arr.length - 1 ; i++) { int minIndex = i; int min = arr[i]; for (int j = i + 1 ; j < arr.length; j++) { if (min > arr[j]) { min = arr[j]; minIndex = j; } } if (minIndex != i) { arr[minIndex] = arr[i]; arr[i] = min; } } } public static void insertSort (int [] arr) for (int i = 1 ; i < arr.length; i++) { int insertValue = arr[i]; int insertIndex = i - 1 ; while (insertIndex >= 0 && insertValue < arr[insertIndex]){ if (insertValue > arr[insertIndex]){ break ; } arr[insertIndex + 1 ] = arr[insertIndex]; insertIndex--; } arr[insertIndex + 1 ] = insertValue; } } public static void shellSort (int [] arr) int temp; for (int gap = arr.length / 2 ; gap > 0 ; gap /= 2 ) { for (int i = gap; i < arr.length; i++){ for (int j = i - gap; j >= 0 ; j -= gap){ if (arr[j] > arr[j + gap]){ temp = arr[j]; arr[j] = arr[j + gap]; arr[j + gap] = temp; } } } } } public static void shellSort2 (int [] arr) for (int gap = arr.length / 2 ; gap > 0 ; gap /= 2 ) { for (int i = gap; i < arr.length; i++) { int j = i; int temp = arr[j]; if (arr[j] < arr[j - gap]){ while (j - gap >= 0 && temp < arr[j - gap]) { arr[j] = arr[j - gap]; j -= gap; } arr[j] = temp; } } } } public static void quickSort (int [] arr, int left, int right) int lt = left; int rt = right; int pivot = arr[(left + right) / 2 ]; int temp; while (lt < rt){ while (arr[lt] < pivot){ lt += 1 ; } while (arr[rt] > pivot){ rt -= 1 ; } if (lt >= rt){ break ; } temp = arr[lt]; arr[lt] = arr[rt]; arr[rt] = temp; if (arr[lt] == pivot){ rt--; } if (arr[rt] == pivot){ lt++; } } if (lt == rt){ lt++; rt--; } if (left < rt){ quickSort(arr, left, rt); } if (right > lt){ quickSort(arr, lt, right); } } public static void mergeSort (int [] arr, int left, int right, int [] temp) if (left < right) { int mid = (left + right) / 2 ; mergeSort(arr, left, mid, temp); mergeSort(arr, mid + 1 , right, temp); mergeSort(arr, left, mid, right, temp); } } public static void mergeSort (int [] arr, int left, int mid, int right, int [] temp) int i = left; int j = mid + 1 ; int t = 0 ; while (i <= mid && j <= right) { if (arr[i] <= arr[j]) { temp[t] = arr[i]; t++; i++; } else { temp[t] = arr[j]; t++; j++; } } while (i <= mid) { temp[t] = arr[i]; t++; i++; } while (j <= right) { temp[t] = arr[j]; t++; j++; } t = 0 ; int tempLeft = left; while (tempLeft <= right) { arr[tempLeft] = temp[t]; t++; tempLeft++; } } public static void redixSort (int [] arr) int max = arr[0 ]; for (int i = 1 ; i < arr.length; i++) { if (arr[i] > max) { max = arr[i]; } } int maxLength = (max + "" ).length(); int [][] bucket = new int [10 ][arr.length]; int [] counts = new int [10 ]; for (int i = 0 , n = 1 ; i < maxLength; i++, n *= 10 ) { for (int j = 0 ; j < arr.length; j++) { int element = arr[j] / n % 10 ; bucket[element][counts[element]] = arr[j]; counts[element]++; } int index = 0 ; for (int k = 0 ; k < bucket.length; k++) { if (counts[k] != 0 ) { for (int m = 0 ; m < counts[k]; m++) { arr[index++] = bucket[k][m]; } } counts[k] = 0 ; } } } public static void heapSort (int [] arr) int temp = 0 ; System.out.println("堆排序!" ); for (int i = arr.length / 2 - 1 ; i >= 0 ; i--) { adjustHeap(arr, i, arr.length); } for (int j = arr.length - 1 ; j > 0 ; j--) { temp = arr[j]; arr[j] = arr[0 ]; arr[0 ] = temp; adjustHeap(arr, 0 , j); } System.out.println(Arrays.toString(arr)); } public static void adjustHeap (int [] arr, int i, int length) int temp = arr[i]; for (int k = 2 * i + 1 ; k < length; k = k * 2 + 1 ) { if ((k + 1 ) < length && arr[k] < arr[k + 1 ]) { k++; } if (arr[k] > temp) { arr[i] = arr[k]; i = k; } else { break ; } } arr[i] = temp; }
查找算法 查找 是在大量的信息中寻找一个特定的信息元素。在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找。【————百度百科】本文简单介绍了 常见的五种查找算法 线性查找 、二分查找 、插值查找 、斐波那契查找 和 哈希查找 。
线性查找 线性查找 也称为 顺序查找 查找过程为 最后一个/第一个记录开始 直到第一个/最后一个
查找一个值 查找结果只有一个值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static void main (String[] args) int [] arr = {-3 , 5 , 10 , 13 , 10 , 10 , 17 , 10 , 34 , 54 , 10 , 60 }; int index = linearSearchOne(arr, 17 ); if (index == -1 ) { System.out.println("没有查到哦~~~" ); } else { System.out.println("找到了,下标为:" + index); } } public static int linearSearchOne (int [] arr, int target) if (arr == null ) { return -1 ; } for (int i = 0 ; i < arr.length; i++) { if (target == arr[i]) { return i; } } return -1 ; }
查找多个值 查找结果有多个值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static void main (String[] args) int [] arr = {-3 , 5 , 10 , 13 , 10 , 10 , 17 , 10 , 34 , 54 , 10 , 60 }; List<Integer> list = linearSearchMore(arr, 10 ); System.out.println(list); } public static List<Integer> linearSearchMore (int [] arr, int target) List<Integer> list = new ArrayList<>(); if (arr == null ) { return list; } for (int i = 0 ; i < arr.length; i++) { if (target == arr[i]) { list.add(i); } } return list; }
二分查找 二分查找 也称 折半查找(Binary Search) 二分查找优点: 比较次数少,查找速度快,平均性能好。 二分查找缺点: 要求待查表为有序表,且插入删除困难。 适用范围: 适用于不经常变动而查找频繁的有序列表
算法复杂度:
假设其数组长度为 n ,其算法复杂度为 O(log(n)) 。
算法思想:
首先,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
二分查找-递归 二分查找递归图解:
二分查找-递归(只查找一个值)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void main (String[] args) int [] arr = {10 , 20 , 30 , 40 , 50 , 60 , 70 , 80 , 90 }; int res = binarySearchOne(arr, 0 , arr.length - 1 , 10 ); System.out.println(res); } public static int binarySearchOne (int [] arr, int left, int right, int target) if (arr == null || left > right) { return -1 ; } int mid = (left + right) / 2 ; int midVal = arr[mid]; if (target > midVal) { return binarySearchOne(arr, mid + 1 , right, target); } else if (target < midVal) { return binarySearchOne(arr, left, mid - 1 , target); } else { return mid; } }
二分查找-递归(查找多个值)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public static void main (String[] args) int [] arr = {10 , 20 , 30 , 30 , 30 , 30 , 40 , 50 , 60 , 70 , 80 , 90 }; List<Integer> list = binarySearchMore(arr, 0 , arr.length - 1 , 30 ); System.out.println(list); } public static List<Integer> binarySearchMore (int [] arr, int left, int right, int findVal) if (arr == null || left > right) { return new ArrayList<>(); } int mid = (left + right) / 2 ; int midVal = arr[mid]; if (findVal > midVal) { return binarySearch(arr, mid + 1 , right, findVal); } else if (findVal < midVal) { return binarySearch(arr, left, mid - 1 , findVal); } else { List<Integer> resIndexlist = new ArrayList<Integer>(); int temp = mid - 1 ; while (true ) { if (temp < 0 || arr[temp] != findVal) { break ; } resIndexlist.add(temp); temp -= 1 ; } resIndexlist.add(mid); temp = mid + 1 ; while (true ) { if (temp > arr.length - 1 || arr[temp] != findVal) { break ; } resIndexlist.add(temp); temp += 1 ; } Collections.sort(resIndexlist); return resIndexlist; } }
二分查找-非递归 二分查找-非递归(只有一个值)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static void main (String[] args) int [] arr = {10 , 20 , 30 , 30 , 30 , 30 , 40 , 50 , 60 , 70 , 80 , 90 }; int value = binarySearchOne(arr, 40 ); System.out.println(value); } public static int binarySearchOne (int [] arr, int target) int left = 0 ; int right = arr.length - 1 ; while (left <= right) { int mid = (left + right) / 2 ; if (arr[mid] == target) { return mid; } else if (arr[mid] > target) { right = mid - 1 ; } else { left = mid + 1 ; } } return -1 ; }
二分查找-非递归(查找多个值)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 public static void main (String[] args) int [] arr = {10 , 20 , 30 , 30 , 30 , 30 , 40 , 50 , 60 , 70 , 80 , 90 }; List list = binarySearchMore(arr, -10 ); System.out.println(list); } public static List<Integer> binarySearchMore (int [] arr, int value) List<Integer> list = new ArrayList<>(); int left = 0 ; int right = arr.length - 1 ; while (left <= right) { int mid = (left + right) / 2 ; if (arr[mid] == value) { int temp = mid - 1 ; while (true ) { if (temp < 0 || arr[temp] != value) { break ; } list.add(temp); temp -= 1 ; } list.add(mid); temp = mid + 1 ; while (true ) { if (temp > arr.length || arr[temp] != value) { break ; } list.add(temp); temp += 1 ; } break ; } else if (arr[mid] > value) { right = mid - 1 ; } else { left = mid + 1 ; } } Collections.sort(list); return list; }
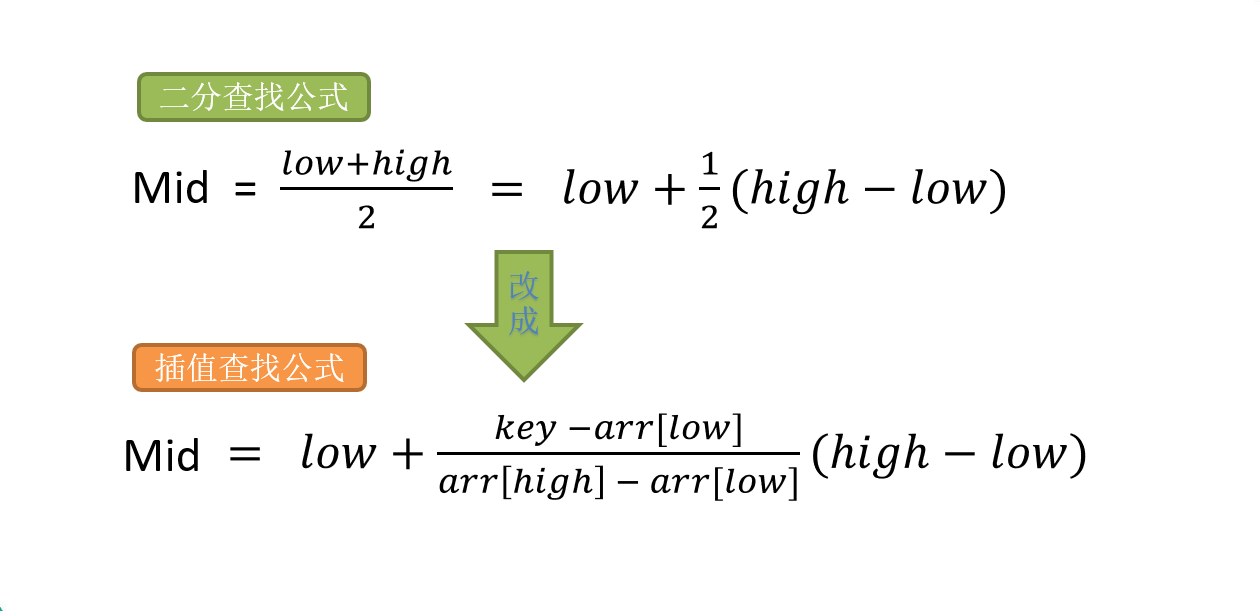
插值查找 插值查找算法 类似于二分查找,不同的是插值查找每次从 自适应 mid 处 开始查找。将折半查找中的求 mid 索引的公式进行改造 , low 表示左边索引 left, high 表示右边索引 right. key 就是我们要查找的值
举两个例子来说明 插值查找的快速
查找一个值 插值查找(只有一个值)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public static void main (String[] args) int [] arr = {1 , 2 , 3 , 4 , 5 , 5 , 5 , 5 , 5 , 6 , 7 , 9 }; int valueSearch = insertValueSearch(arr, 0 , arr.length - 1 , 5 ); System.out.println(valueSearch); } public static int insertValueSearch (int [] arr, int left, int right, int findVal) System.out.println("插值查找次数~~" ); if (left > right || findVal < arr[0 ] || findVal > arr[arr.length - 1 ]) { return -1 ; } int mid = left + (right - left) * (findVal - arr[left]) / (arr[right] - arr[left]); int midVal = arr[mid]; if (findVal > midVal) { return insertValueSearch(arr, mid + 1 , right, findVal); } else if (findVal < midVal) { return insertValueSearch(arr, left, mid - 1 , findVal); } else { return mid; } }
查找多个值 插值查找(有多个值)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 public static void main (String[] args) int [] arr = {1 , 2 , 3 , 4 , 5 , 5 , 5 , 5 , 5 , 6 , 7 , 9 }; List valueSearch = insertValueSearch(arr, 0 , arr.length - 1 , 5 ); System.out.println(valueSearch); } public static List<Integer> insertValueSearch (int [] arr, int left, int right, int findVal) System.out.println("插值查找次数~~" ); if (left > right || findVal < arr[0 ] || findVal > arr[arr.length - 1 ]) { return new ArrayList<>(); } int mid = left + (right - left) * (findVal - arr[left]) / (arr[right] - arr[left]); int midVal = arr[mid]; if (findVal > midVal) { return insertValueSearch(arr, mid + 1 , right, findVal); } else if (findVal < midVal) { return insertValueSearch(arr, left, mid - 1 , findVal); } else { ArrayList<Integer> arrayList = new ArrayList<>(); int temp = mid - 1 ; while (true ) { if (temp < 0 || arr[temp] != findVal) { break ; } arrayList.add(temp); temp--; } arrayList.add(mid); temp = mid + 1 ; while (true ) { if (temp > arr.length || arr[temp] != findVal) { break ; } arrayList.add(temp); temp++; } return arrayList; } }
注意事项:
1、 数据量较大,关键字分布比较均匀 插值查找 2、 关键字分布不均匀
斐波那契查找 黄金分割 黄金分割 是指将整体 一分为二 较大部分与整体部分的比值 较小部分与较大部分的比值 0.618 。这个比例被公认为是最能引起美感的比例,因此被称为 黄金分割 。由于按此比例设计的造型十分美丽,也称为 中外比 斐波那契数列 {1, 1, 2, 3, 5, 8, 13, 21, 34, 55 } 黄金分割值 0.618 斐波那契查找算法 。
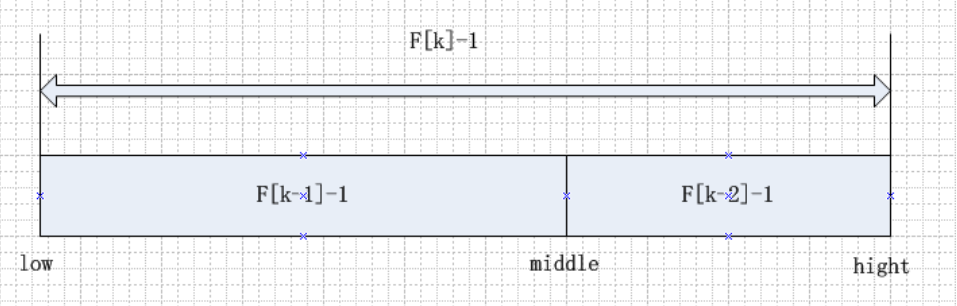
斐波那契原理 斐波那契思想 与二分法相类似,不过中间点不再是中点,而变成了 黄金分割点 mid = low + F(k - 1) - 1 , F 代表斐波那契数列,以下将对 F(k - 1) - 1 进行解释,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 1 、F 代表的斐波那契数列,k 代表斐波那契数列的第 k 个元素 2 、由 F[k] = F[k-1] + F[k-2] 可以得知,可以得到 F[k] - 1 = (F[k-1] - 1 ) + (F[k-2] - 1 ) + 1 。 这个式子说明只要是顺序表的长度为 F[k] - 1 ,就可以分为 (F[k-1] - 1 ) 和 (F[k-2] - 1 ) 两段,另外一个 1 就是 mid 位置的元素 3 、类似的每一个子段也可以用同样的方式来进行分隔 4 、但是顺序表的长度不一定是恰好等于 F[k] - 1 ,所以需要将原来的顺序表的长度增加到 F[k] - 1 , 这里的 k 值仅仅需要使得 F[k] - 1 恰好大于或者等于 n ,新增的位置的值,都赋值为下标是 n - 1 位置的值
代码实现 斐波那契查找(只有一个值)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 public class FibonacciSearch public static int maxSize = 25 ; public static void main (String[] args) int [] arr = {1 , 8 , 10 , 89 , 1000 , 1234 }; int res = fibSearch(arr, 1000 ); System.out.println("index = " + res); } public static int [] fib() { int [] arr = new int [maxSize]; arr[0 ] = 1 ; arr[1 ] = 1 ; for (int i = 2 ; i < maxSize; i++) { arr[i] = arr[i - 1 ] + arr[i - 2 ]; } return arr; } public static int fibSearch (int [] arr, int key) int low = 0 ; int high = arr.length - 1 ; int k = 0 ; int mid = 0 ; int fib[] = fib(); while (high > fib[k] - 1 ) { k++; } int [] temp = Arrays.copyOf(arr, fib[k]); for (int i = high + 1 ; i < temp.length; i++) { temp[i] = arr[high]; } while (low <= high) { mid = low + fib[k - 1 ] - 1 ; if (key < temp[mid]) { high = mid - 1 ; k--; } else if (key > temp[mid]) { low = mid + 1 ; k -= 2 ; } else { if (mid <= high) { return mid; } else { return high; } } } return -1 ; } }
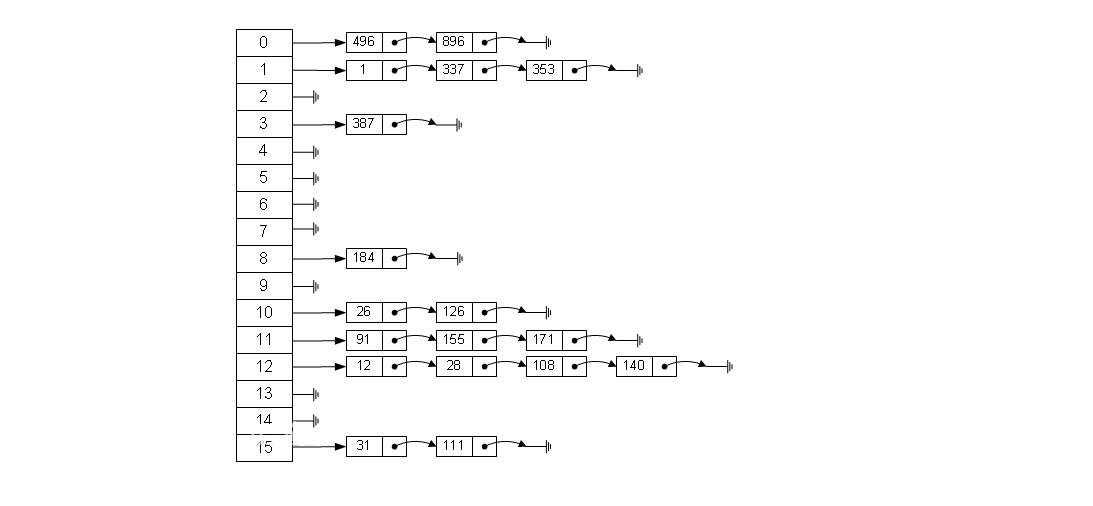
哈希表 基本介绍 散列表 哈希表 ),是根据 关键码值 (Key value) 散列函数 ,存放记录的数组叫做 散列表 。如下图:
问题描述
Google 公司的一个上机题:
有一个公司,当有新的员工来报道时,要求将该 员工的信息【id,性别,年龄,名字,住址..】 要求: 不使用数据库,速度越快越好
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 import java.util.Scanner;public class HashTabTest public static void main (String[] args) HashTab hashTab = new HashTab(7 ); String key; Scanner scanner = new Scanner(System.in); while (true ) { System.out.println("add: 添加雇员" ); System.out.println("list: 显示雇员" ); System.out.println("find: 查找雇员" ); System.out.println("exit: 退出系统" ); key = scanner.next(); switch (key) { case "add" : System.out.println("请输入 id:" ); int id = scanner.nextInt(); System.out.println("请输入名字:" ); String name = scanner.next(); Emp emp = new Emp(id, name); hashTab.add(emp); break ; case "list" : hashTab.list(); break ; case "find" : System.out.println("请输入要查找的 id:" ); id = scanner.nextInt(); hashTab.findEmpById(id); break ; case "exit" : scanner.close(); System.exit(0 ); default : break ; } } } } class HashTab private EmpLinkedList[] empArray; private int size; public HashTab (int size) this .size = size; empArray = new EmpLinkedList[size]; for (int i = 0 ; i < size; i++) { empArray[i] = new EmpLinkedList(); } } public void add (Emp emp) int empLinkedListNO = hashFun(emp.id); empArray[empLinkedListNO].add(emp); } public void list () for (int i = 0 ; i < size; i++) { empArray[i].list(i); } } public void findEmpById (int id) int empLinkedListNO = hashFun(id); Emp emp = empArray[empLinkedListNO].findEmpById(id); if (emp != null ) { System.out.printf("在第%d条链表中找到雇员 id = %d\n" , (empLinkedListNO + 1 ), id); } else { System.out.println("在哈希表中,没有找到该雇员~~~" ); } } public int hashFun (int id) return id % size; } } class Emp public int id; public String name; public Emp next; public Emp (int id, String name) super (); this .id = id; this .name = name; } } class EmpLinkedList private Emp head; public void add (Emp emp) if (head == null ) { head = emp; return ; } Emp curEmp = head; while (true ) { if (curEmp.next == null ) { break ; } curEmp = curEmp.next; } curEmp.next = emp; } public void list (int no) if (head == null ) { System.out.println("第 " + (no + 1 ) + " 条链表为空" ); return ; } System.out.print("第 " + (no + 1 ) + " 条链表的信息为" ); Emp curEmp = head; while (true ) { System.out.printf(" => id=%d name=%s " , curEmp.id, curEmp.name); if (curEmp.next == null ) { break ; } curEmp = curEmp.next; } System.out.println(); } public Emp findEmpById (int id) if (head == null ) { System.out.println("链表为空" ); return null ; } Emp curEmp = head; while (true ) { if (curEmp.id == id) { break ; } if (curEmp.next == null ) { curEmp = null ; break ; } curEmp = curEmp.next; } return curEmp; } }
常用的算法 分治算法 分治算法介绍 分治算法 是一种很重要的算法。字面上的解释是 “分而治之” ,就是把一个 复杂的问题 子问题
分治算法可以求解的一些经典问题:
1、二分搜索 2、大整数乘法 3、棋盘覆盖
4、合并排序 5、快速排序 6、线性时间选择
7、最接近点对问题 8、循环赛日程表 9、汉诺塔问题
求解步骤 分治算法 在每一层递归上都有以下 三个步骤 :
求解步骤:
1、分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题
2、解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
3、合并:将各个子问题的解合并为原问题的解。
应用:汉诺塔问题 汉诺塔的传说: 汉诺塔(又称河内塔)问题 是源于印度一个古老传说的 益智玩具 5845.54 亿年 5845.54 亿年
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static void hanoiTower (int num, char L, char M, char R) if (num == 1 ){ System.out.println("第" + num + "个盘从 " + L + "-->" + R); }else { hanoiTower(num - 1 , L, R, M); System.out.println("第" + num + "个盘从 " + L + "-->" + R); hanoiTower(num - 1 , M , L , R); } }
TIPS : 分治算法理解起来容易,就是分而治之。但关键在于: 如何划分,如何把整体划分成部分。解决划分问题,分治算法就算掌握了。
动态规划算法 算法介绍 动态规划(Dynamic Programming)算法 的 核心思想 与分治法不同的是 填表的方式
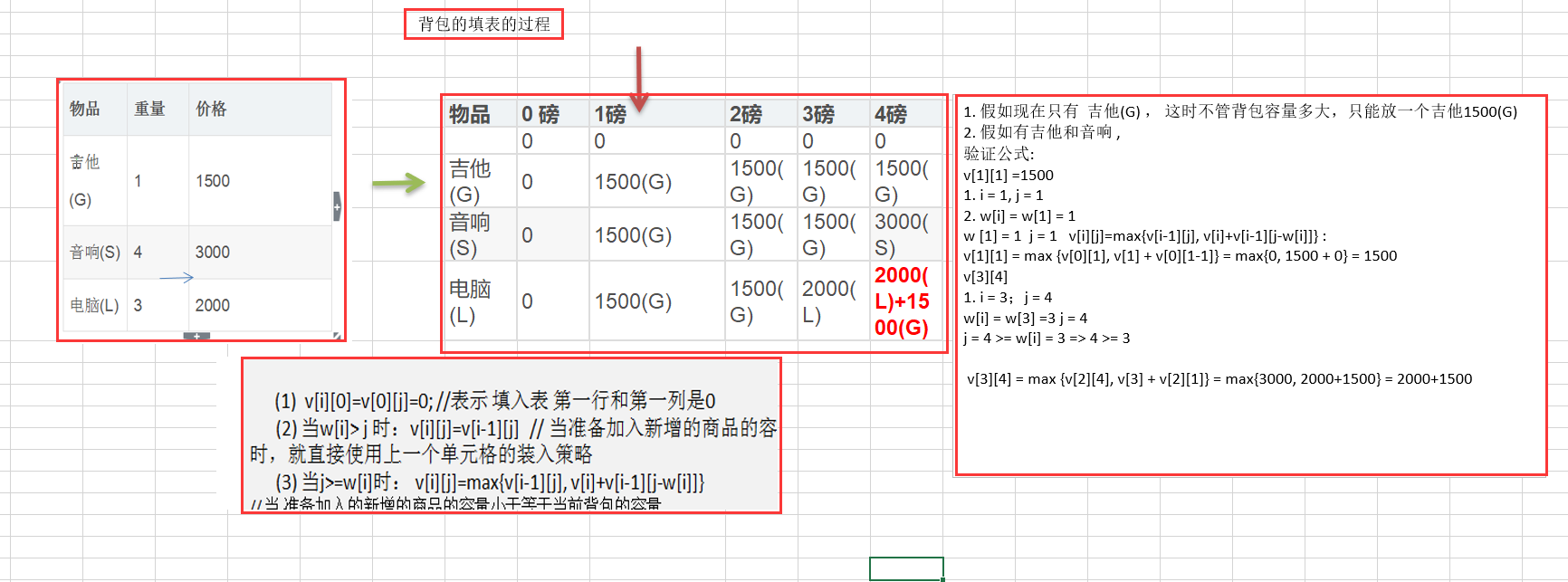
应用:背包问题 背包问题:有一个背包,容量为 4 磅 , 现有如下物品:
物品
重量
价格
吉他(G)
1
1500
音响(S)
4
3000
电脑(L)
3
2000
问题要求:
思路分析
代码演示 动态规划算法的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 package edu.jgsu.algorithm;public class KnapsackProblem public static void main (String[] args) int [] w = {1 ,4 ,2 }; int [] val = {1500 ,3000 ,2000 }; int n = val.length; int m = 4 ; int [][] v = new int [n+1 ][m+1 ]; int [][] path = new int [n+1 ][m+1 ]; for (int i = 0 ; i < v.length; i++) { v[i][0 ] = 0 ; } for (int i=0 ; i < v[0 ].length; i++) { v[0 ][i] = 0 ; } for (int i =0 ; i < v.length;i++) { for (int j = 0 ; j < v[i].length;j++) { System.out.print(v[i][j] + " " ); } System.out.println(); } System.out.println("============================" ); for (int i = 1 ; i < v.length; i++) { for (int j=1 ; j < v[0 ].length; j++) { if (w[i-1 ]> j) { v[i][j]=v[i-1 ][j]; } else { if (v[i - 1 ][j] < val[i - 1 ] + v[i - 1 ][j - w[i - 1 ]]) { v[i][j] = val[i - 1 ] + v[i - 1 ][j - w[i - 1 ]]; path[i][j] = 1 ; } else { v[i][j] = v[i - 1 ][j]; } } } } for (int i =0 ; i < v.length;i++) { for (int j = 0 ; j < v[i].length;j++) { System.out.printf("%04d " ,v[i][j]); } System.out.println(); } System.out.println("============================" ); int i = path.length - 1 ; int j = path[0 ].length - 1 ; while (i > 0 && j > 0 ) { if (path[i][j] == 1 ) { System.out.printf("第%d个商品放入到背包\n" , i); j -= w[i-1 ]; } i--; } } }
暴力匹配算法 算法介绍
代码演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static int violenceMatch (String str1, String str2) char [] s1 = str1.toCharArray(); char [] s2 = str2.toCharArray(); int s1Len = s1.length; int s2Len = s2.length; int i = 0 ; int j = 0 ; while (i < s1Len && j < s2Len) { if (s1[i] == s2[j]) { i++; j++; } else { i = i - (j - 1 ); j = 0 ; } } if (j == s2Len) { return i - j; } else { return -1 ; } }
KMP 算法 算法介绍
TIPS :
KMP 算法关键: 部分匹配表 next 数组 参考文章: https://www.cnblogs.com/zzuuoo666/p/9028287.html
代码演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public class KMPAlgorithm public static void main (String[] args) String str1 = "BBC ABCDAB ABCDABCDABDE" ; String str2 = "ABCDABD" ; int [] next = kmpNext("ABCDABD" ); System.out.println("next=" + Arrays.toString(next)); int index = kmpSearch(str1, str2, next); System.out.println("index=" + index); } public static int kmpSearch (String str1, String str2, int [] next) for (int i = 0 , j = 0 ; i < str1.length(); i++) { while ( j > 0 && str1.charAt(i) != str2.charAt(j)) { j = next[j-1 ]; } if (str1.charAt(i) == str2.charAt(j)) { j++; } if (j == str2.length()) { return i - j + 1 ; } } return -1 ; } public static int [] kmpNext(String dest) { int [] next = new int [dest.length()]; next[0 ] = 0 ; for (int i = 1 , j = 0 ; i < dest.length(); i++) { while (j > 0 && dest.charAt(i) != dest.charAt(j)) { j = next[j-1 ]; } if (dest.charAt(i) == dest.charAt(j)) { j++; } next[i] = j; } return next; } }
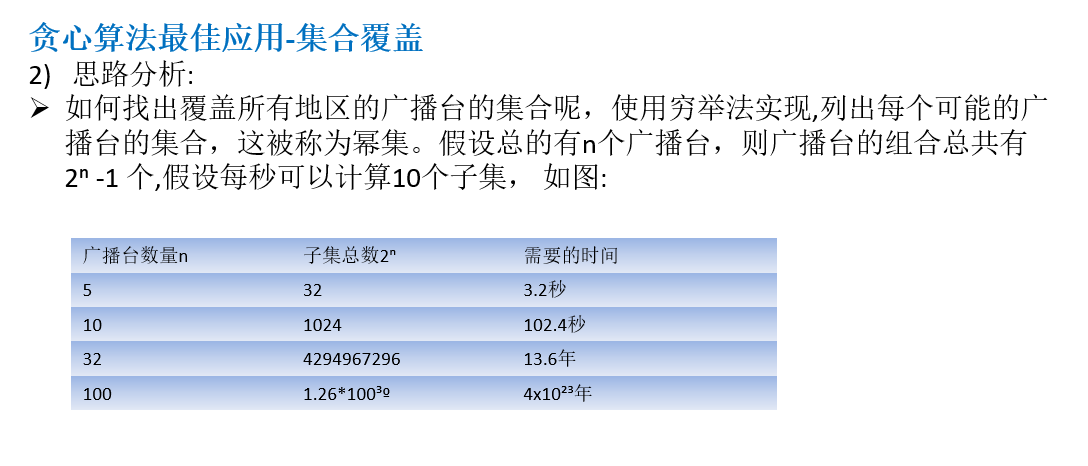
贪心算法 算法介绍
应用场景及分析
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 package greedy;import java.util.*;public class Greedy public static void main (String[] args) Map<String, HashSet<String>> broadcast = new HashMap<>(); HashSet<String> hashSet1 = new HashSet<>(); hashSet1.add("北京" ); hashSet1.add("上海" ); hashSet1.add("天津" ); HashSet<String> hashSet2 = new HashSet<>(); hashSet2.add("广州" ); hashSet2.add("北京" ); hashSet2.add("深圳" ); HashSet<String> hashSet3 = new HashSet<>(); hashSet3.add("成都" ); hashSet3.add("上海" ); hashSet3.add("杭州" ); HashSet<String> hashSet4 = new HashSet<>(); hashSet4.add("上海" ); hashSet4.add("天津" ); HashSet<String> hashSet5 = new HashSet<>(); hashSet5.add("杭州" ); hashSet5.add("大连" ); broadcast.put("K1" , hashSet1); broadcast.put("K2" , hashSet2); broadcast.put("K3" , hashSet3); broadcast.put("K4" , hashSet4); broadcast.put("K5" , hashSet5); HashSet<String> allAreas = new HashSet<>(); Set<Map.Entry<String, HashSet<String>>> entries = broadcast.entrySet(); for (Map.Entry<String, HashSet<String>> entry : entries) { HashSet<String> value = entry.getValue(); for (String s : value) { allAreas.add(s); } } System.out.println(allAreas); ArrayList<String> selects = new ArrayList<>(); HashSet<String> tempSet = new HashSet<>(); String maxKey = null ; while (allAreas.size() != 0 ) { maxKey = null ; for (String key : broadcast.keySet()) { tempSet.clear(); HashSet<String> areas = broadcast.get(key); tempSet.addAll(areas); tempSet.retainAll(allAreas); if (tempSet.size() > 0 && (maxKey == null || tempSet.size() > broadcast.get(maxKey).size())) { maxKey = key; } } if (maxKey != null ) { selects.add(maxKey); allAreas.removeAll(broadcast.get(maxKey)); } } System.out.println("贪心算法最后结果:--- " + selects); } }
注意事项
普利姆算法 克鲁斯卡尔算法 迪杰斯特拉算法 弗洛伊德算法 回溯算法 八皇后算法 骑士周游算法 番外篇,哈哈 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 数据结构:逻辑结构和物理结构(数据在计算机内部的物理存储方式) 数据元素存储形式:顺序存储结构和链式存储结构(银行排队叫号系统) 逻辑结构:集合结构、线性结构、树形结构(金字塔关系)、图形结构 了解:六度空间理论 了解算法:就是解决问题的方法。例如:求从1加到100的和。使用for循环和等差公式,对计算机来说都没有什么差别,但加到10000000就差别大了,这就是算法。 算法5个特性:零个或多个输入、至少一个或多个输出、有穷性、确定性和可行性。 算法设计要求:正确性、可读性、健壮性、时间效率高和存储量低。 时间复杂度(渐近时间复杂度):使用大O体现算法时间复杂度,成为大O计法。 线性阶:非嵌套循环涉及线性阶,对应次数成直线增长。 平方阶:两个嵌套循环涉及平方阶。 对数阶:例如下面的程序:2的x次方=n,求解之后x=log(2)n,所以时间复杂度为O(logn) 还有常数阶,立方阶,指数阶。nlogn阶。 int i = 1, n = 100; while(i < n) { i = i * 2; } 最坏情况: 平均情况:平均运行时间就是期望运行时间。 空间复杂度:写代码时,可以用空间换取时间。闰年算法的例子。 线性表: 存和读的情况:时间复杂度为O(1) 插入和删除情况:时间复杂度为O(n) 单链表: 结点:数据域和指针域合在一起叫做结点 数据域:存放数据的地方 指针域:存放下一个地址的地方 第一个结点叫做头结点(头指针)头结点一般不存储任何东西,头指针指向头结点,最后一个结点指向NULL 下一次看线性表第6集 ====================================== 认识时间复杂度,用big O表示 二分搜索,时间复杂度O(log2N) 外排(谁小谁移动) 题目:给定一个M个数的数组a和N个数的数组B,数组a乱序,数组b顺序,求两个数组共有多少个相同的数的复杂度? 第一种:嵌套for循环,复杂度为O(M*N) 第二种:对数组b(数组b是顺序的)使用二分查找,时间复杂度O(M*log2N) 第三种:使用外排,先对数组a进行排序,然后使用外排,就是将两个数组的索引指向0,指向数字谁小谁就往下移动一个位置,直到结束。 选择排序: 第一次排序把最小的放在第一位,第二次排序把第二小的数字放在第二位,以此类推,直至结束。 这种排序和数据状况没有关系,即便是一个排好的数组,它的时间复杂度仍然不变。 冒泡排序: 在一个数组中,相邻位置的数进行比较。进行完第一轮排序,最大的数字会在最后一个位置。那么下一轮排序就不用比较最后一个数字了。 这种排序和数据状况没有关系,即便是一个排好的数组,它的时间复杂度仍然不变。 插入排序: 就像打扑克牌一样,一副排好序的牌,然后你摸了一张牌,就要给这张牌找位置,这就是插入排序。 插入排序和数据状况有关,例如:数组元素1,2,3,4,5,那么插入排序复杂度为O(N),如果是5,4,3,2,1,那么复杂度为O(N2). 一般情况下,都是按照最坏情况作为一个算法的复杂度。 最好情况: 平均情况: 最坏情况: 以上三种情况在插入排序可见,自己百度以下平均情况。 对数器【很重要的】:方法在排序代码里有。先要有随机数组产生器,然后需要绝对正确的方法,接着进行大样本的测试。 堆的结构准备模板,排序、二叉树、数组也要准备对数器模板。 冒泡和选择公司已经不使用了,只具有参考和教学意义。 递归算法:1:38:26 递归如何求时间复杂度?1:51:49 时间复杂度求解公式1:54:30 归并排序: master公式 复杂度为O(N*log2N) 计算机网络看视频从第一章开始看,同时参观CSDN别人的博客。 =============================== 韩顺平老师数据结构: =============================== KMP算法: 汉诺塔问题:使用分治算法 八皇后问题:使用回溯算法 骑士周游问题:DFS+贪心算法 场合不同,所使用的算法不一样 五子棋程序 约瑟夫问题【单向环形链表】 稀疏数组和队列 队列的应用:队列是个有序列表,可以用数组或者链表实现。特点:先进先出 队列加数据在尾部加入,且rear+1,取数据在头部取,且front+1。 queue包里面代码:数组实现队列和链表实现队列。 数组模拟成环形队列。 栈的应用:如子弹的弹夹,最先压入的子弹最后打出。 线性表:自己补充 单链表知识:看完写博客 双向链表: (环形链表)约瑟夫环: 排序算法: 内容在 PPT 上 已看:50 51 冒泡排序: 选择排序: 插入排序: 希尔排序: 快速排序: 归并排序: 基数排序: 桶排序: 堆排序: 计数排序: 查找算法: 顺序(线性)查找: 二分查找/折半查找: 插值查找: 非常的牛逼 斐波那契查找(黄金分割查找): 哈希表: 二叉树: - 各种二叉树术语 - 三种遍历方式 - 二叉树的查找 - 二叉树的删除 - 顺序存储二叉树 - 线索化二叉树 - 堆排序:先变成大顶堆,然后排序 赫夫曼树: wpl最小的就是赫夫曼树,赫夫曼树也是二叉树 赫夫曼编码:不要前缀编码,就是不要出现二义性 赫夫曼压缩 赫夫曼解压 二叉排序树: - 创建 - 遍历 - 删除 平衡二叉树: - 左旋转 - 右旋转 - 双旋转 多叉树: B树 - 2-3树 - 234树 B+树 B*树 多路查找树 图: 图的基本术语 图的邻接矩阵 图的邻接表 图的遍历方式: - 深度优先遍历(DFS) - 广度优先遍历(BFS) 想要理解清楚 DFS 和 BFS 的区别,就要以图的邻接矩阵为例子,更好理解一点。 程序员常用的 10 中算法: - 二分查找算法(非递归) - 分治算法(汉诺塔问题)【使用了递归算法】 - 动态规划算法(背包问题) - KMP 算法(字符串匹配问题) - 暴力匹配算法 - 贪心算法 - 普利姆算法(prim算法)(修路问题)(最小生成树问题) - 克鲁斯卡尔算法(公交站问题) - 迪杰斯特拉算法(最短路径问题) - 弗洛伊德算法 - 马踏棋盘算法(骑士周游问题) 卖油翁和老黄牛的故事: 在通往成功的路上,我们必须坚持,不要中途放弃,自毁前程,而要勇往直前,坚持不懈,最终会抵达理想的彼岸。既然选择了远方,便只顾风雨兼程。
其他算法小案例 反转输出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void xiaomi () Scanner sc = new Scanner(System.in); System.out.println("请输入句子,以空格分隔:" ); String str = sc.nextLine(); String[] arr = str.split(" " ); for (int i = 0 ; i < arr.length; i++) { System.out.print(arr[arr.length - 1 - i] + " " ); } }
十进制和十六进制转化 1 2 3 4 5 6 7 8 9 10 11 public static String intToHex (int n) StringBuffer s = new StringBuffer(); String a; char [] b = {'0' , '1' , '2' , '3' , '4' , '5' , '6' , '7' , '8' , '9' , 'a' , 'b' , 'c' , 'd' , 'e' , 'f' }; while (n != 0 ) { s = s.append(b[n % 16 ]); n = n / 16 ; } a = s.reverse().toString(); return a; }
杨辉三角 1 2 3 4 5 6 7 8 9 10 11 12 13 public static void yanghui (int rows) for (int i = 0 ; i < rows; i++) { int number = 1 ; System.out.format("%" + (rows - i) * 2 + "s" , "" ); for (int j = 0 ; j <= i; j++) { System.out.format("%4d" , number); number = number * (i - j) / (j + 1 ); } System.out.println(); } }
格式化数组 1 2 3 4 5 6 7 8 9 10 11 public static void arrayFormat (int [] arr) System.out.print("[" ); for (int i = 0 ; i < arr.length; i++) { if (i == arr.length -1 ) { System.out.print(arr[i] + "#]" ); } else { System.out.print(arr[i] + "# " ); } } }