内容概要:
File 类 File 概述 java.io.File 类是文件和目录路径名的抽象表示,主要用于文件和目录的创建、查找和删除等操作。具体功能如下:
具体功能:
创建一个文件/文件夹
删除文件/文件夹
获取文件/文件夹
判断文件/文件夹是否存在
对文件夹进行遍历
获取文件的大小
输出路径分隔符和文件名称分隔符的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) String pathSeparator = File.pathSeparator; System.out.println(pathSeparator); char pathSeparatorChar = File.pathSeparatorChar; System.out.println(pathSeparatorChar); String separator = File.separator; System.out.println(separator); char separatorChar = File.separatorChar; System.out.println(separatorChar); }
构造方法
构造方法:
public File(String pathname) :通过将给定的路径名字符串转换为抽象路径名来创建新的 File 实例。
public File(String parent, String child) :从父路径名字符串和子路径名字符串创建新的 File 实例。
public File(File parent, String child) :从父抽象路径名和子路径名字符串创建新的 File 实例。
构造方法代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main (String[] args) File file01 = new File("F:\\00-BLOG-HOME\\themes\\icarus-latest\\layout\\widget" ); System.out.println(file01); File file02 = new File("F:\\" , "00-BLOG-HOME" ); System.out.println(file02); File parent = new File("F:\\" ); File file03 = new File(parent, "00-BLOG-HOME" ); System.out.println(file03); }
小贴士: 一个 File 对象代表硬盘中实际存在的一个文件或者目录,无论该路径下是否存在文件或者目录,都不影响 File 对象的创建。
常用方法 获取功能的方法
获取功能的方法
public String getAbsolutePath() :返回此 File 的绝对路径名字符串。
public String getPath() :将此 File 转换为路径名字符串。
public String getName() :返回由此 File 表示的文件或目录的名称。
public long length() :返回由此 File 表示的文件的长度。
方法演示,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public static void main (String[] args) File file01 = new File("F:\\00-BLOG-HOME\\themes\\icarus-latest\\layout\\widget" ); System.out.println(file01.getAbsolutePath()); File file02 = new File("00-BLOG-HOME" ); System.out.println(file02.getAbsolutePath()); System.out.println(file01.getPath()); System.out.println(file02.getPath()); System.out.println(file01); System.out.println(file01.toString()); System.out.println(file01.getName()); System.out.println(file02.getName()); File file04 = new File("F:\\00-BLOG-HOME\\source\\about\\index.md" ); System.out.println(file04.length()); File file05 = new File("F:\\00-BLOG-HOME\\source\\about" ); System.out.println(file05.length()); }
判断功能的方法
判断功能的方法
public boolean exists() :此 File 表示的文件或目录是否实际存在。
public boolean isDirectory() :此 File 表示的是否为目录。
public boolean isFile() :此 File 表示的是否为文件。
方法演示,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void main (String[] args) File file01 = new File("F:\\00-BLOG-HOME\\themes\\icarus-latest\\layout\\widget" ); System.out.println(file01.exists()); File file02 = new File("00-BLOG-HOME" ); System.out.println(file02.exists()); if (file01.exists()){ System.out.println(file01.isDirectory()); System.out.println(file01.isFile()); System.out.println(file02.isDirectory()); System.out.println(file02.isFile()); } }
创建和删除功能的方法
创建和删除功能的方法
public boolean createNewFile() :当且仅当具有该名称的文件尚不存在时,创建一个新的空文件。
public boolean delete() :删除由此 File 表示的文件或目录。
public boolean mkdir() :创建由此 File 表示的目录。
public boolean mkdirs() :创建由此 File 表示的目录,包括任何必需但不存在的父目录。
方法演示,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public static void main (String[] args) throws IOException } private static void demo03 () File file05 = new File("F:\\home\\111" ); System.out.println(file05.delete()); } private static void demo02 () File file03 = new File("F:\\home\\啊啊啊" ); System.out.println(file03.mkdir()); File file04 = new File("F:\\home\\111\\啊啊啊" ); System.out.println(file04.mkdirs()); } private static void demo01 () throws IOException File file01 = new File("F:\\home\\01.txt" ); System.out.println(file01.createNewFile()); File file02 = new File("F:\\blog-home\\01.txt" ); System.out.println(file02.createNewFile()); }
目录的遍历 详情看代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void main (String[] args) File file01 = new File("F:\\home" ); String[] list = file01.list(); for (String str : list) { System.out.println(str); } File file02 = new File("F:\\home" ); File[] listFiles = file02.listFiles(); for (File file : listFiles) { System.out.println(file); } }
调用 listFiles 方法的 File 对象,表示的必须是实际存在的目录,否则返回 null,无法进行遍历。
递归 递归概述
递归: 指在当前方法内调用自己的这种现象。递归的分类: 递归分为两种,直接递归和间接递归。直接递归: 方法自身调用自己。间接递归: 可以理解为 A 方法调用 B 方法,B 方法调用 C 方法,C 方法调用 A 方法。注意事项:
递归分析图解:
1 2 3 4 5 6 7 8 9 10 11 12 13 public static void main (String[] args) recursion(1 ); } private static void recursion (int i) if (i > 500 ){ return ; } System.out.println(i); recursion(++i); }
递归累加求和 1 2 3 4 5 6 7 8 9 10 11 public static void main (String[] args) int sum = sum(100 ); System.out.println(sum); } public static int sum (int n) if (n == 1 ) { return 1 ; } return n + sum(n - 1 ); }
递归求阶乘 1 2 3 4 5 6 7 8 9 10 11 public static void main (String[] args) long mul = mul(10 ); System.out.println(mul); } public static long mul (int n) if (n == 1 ){ return 1 ; } return n * mul(n - 1 ); }
递归打印多级目录 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static int count = 0 ;public static void main (String[] args) File file = new File("F:\\home" ); getFiles(file); } public static void getFiles (File file) File[] list = file.listFiles(); for (File s : list) { if (s.isDirectory()){ getFiles(s); } System.out.println(s); System.out.println(++count); } }
文件搜索 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static int count = 0 ;public static void main (String[] args) File file = new File("F:\\home" ); getFiles(file); } public static void getFiles (File file) File[] list = file.listFiles(); for (File s : list) { if (s.isDirectory()) { getFiles(s); } else { if (s.toString().endsWith(".xml" )) { System.out.println(s); System.out.println(++count); } } } }
文件搜索之过滤器
文件过滤器:
1、java.io.FileFilter 是一个接口,是 File 的过滤器。该接口的对象可以传递给 File 类的 listFiles(FileFilter) 作为参数。
2、接口中只有一个方法 boolean accept(File pathname) ,测试 pathname 是否应该包含在当前 File 目录中,符合则返回 true。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 static int count = 0 ;public static void main (String[] args) File file = new File("F:\\home" ); getFiles(file); } public static void getFiles (File file) File[] list = file.listFiles(new FileFilter() { @Override public boolean accept (File pathname) if (pathname.isDirectory()){ return true ; } return pathname.getName().toLowerCase().endsWith(".xml" ); } }); for (File s : list) { if (s.isDirectory()) { getFiles(s); } else { if (s.toString().endsWith(".xml" )) { System.out.println(s); System.out.println(++count); } } } }
过滤器之 Lambda 优化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static int count = 0 ; public static void main (String[] args) File file = new File("F:\\home" ); getFiles(file); System.out.println("\n匹配到的合适的文件个数:" + count + "个" ); } public static void getFiles (File file) File[] list = file.listFiles(pathname-> pathname.isDirectory() || pathname.getName().toLowerCase().endsWith(".xml" )); for (File s : list) { if (s.isDirectory()) { getFiles(s); } else { if (s.toString().endsWith(".xml" )) { System.out.println(s); count++; } } } }
IO 流概述 什么是 IO 流 当你电脑上插入一个U盘,可以把一个视频,拷贝到你的电脑硬盘里。我们把这种数据的传输,可以看做是一种数据的流动,称之为 IO 流 。按照流动的方向,以内存为基准,分为 输入流 input 和 输出流 output ,即流向内存是输入流,流出内存的输出流。如下草图:
Java 中 IO 操作主要是指使用 java.io 包下的内容所进行的输入、输出操作。输入 也叫做读取数据,输出 也叫做作写出数据。
IO 流的分类
根据数据的流向分:
输入流 :把数据从其他设备上读取到内存中的流。
输出流 :把数据从内存中写出到其他设备上的流。
根据数据的类型分:
字节流 :以字节为单位,读写数据的流。
字符流 :以字符为单位,读写数据的流。
根据分类不同,IO 流所对应的类也有所不同,如下表:
输入流 输出流
字节流 字节输入流InputStream
字节输出流OutputStream
字符流 字符输入流Reader
字符输出流Writer
IO 流的简单介绍就到这里了,下面将详细介绍 Java 中的 IO 流。请往下阅读 👇👇👇
字节流 一切皆为字节 一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都是一个一个的字节,那么在传输时一样如此。所以,字节流可以传输任意文件数据。在操作流的时候,我们要时刻明确,无论使用什么样的流对象,底层传输的始终为二进制数据。
字节输出流 java.io.OutputStream 抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。
字节输出流的通用方法:
public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
public void write(byte[] b) :将 b.length 字节从指定的字节数组写入此输出流。
public void write(byte[] b, int off, int len) :从指定的字节数组写入 len 字节,从偏移量 off 开始输出到此输出流。
public abstract void write(int b) :将指定的字节输出流。
FileOutputStream 类 OutputStream 有很多子类,我们从最简单的一个子类 java.io.FileOutputStream 开始。这个类是文件输出流,用于将数据写出到文件,也就是从内存把数据写出到硬盘上。
写出数据的原理(内存 --> 硬盘):
java 程序 --> JVM(java 虚拟机) --> OS(操作系统) --> OS 调用写数据的方法 --> 把数据写入到文件中
字节输出流的使用步骤(重点):
1、创建一个 FileOutputStream 对象,构造方法中传递写入数据的目的地
2、调用 FileOutputStream 对象中的方法 write ,把数据写入到文件中
3、释放资源(IO 流操作会占用一定的内存,使用完毕要把内存清空,提供程序的效率)
构造方法
构造方法:
public FileOutputStream(File file) : 创建文件输出流以写入由指定的 File 对象表示的文件。
public FileOutputStream(String name) : 创建文件输出流以指定的名称写入文件。
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有这个文件,会创建该文件。如果有这个文件,会清空这个文件的数据。上述两种构造方法举例,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void main (String[] args) throws Exception File file = new File("F:\\home\\02.txt" ); FileOutputStream fos = new FileOutputStream(file); FileOutputStream fileOutputStream = new FileOutputStream("F:\\home\\03.txt" ); fileOutputStream.close(); fos.close(); }
写出字节数据 通过 write(int b) 方法,每次可以写出一个字节数据,代码使用演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void main (String[] args) throws IOException FileOutputStream fos = new FileOutputStream("F:\\home\\fos.txt" ); fos.write(97 ); fos.write(98 ); fos.write(99 ); fos.close(); }
小贴士:
1、虽然参数为 int 类型四个字节,但是只会保留一个字节的信息写出。
写出字节数组 通过 write(byte[] b) 方法,每次可以写出数组中的数据,代码使用演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public static void main (String[] args) throws Exception public static void main (String[] args) throws Exception FileOutputStream fileOutputStream = new FileOutputStream("F:\\home\\03.txt" ); FileOutputStream fos = new FileOutputStream("F:\\home\\04.txt" ); byte [] arr = {65 , 66 , 67 , 68 , 69 }; fileOutputStream.write(arr); byte [] bytes = {-65 , -66 , -67 , 68 , 69 }; fos.write(bytes); fos.write(arr, 1 , 2 ); byte [] str = "你好" .getBytes(); System.out.println(Arrays.toString(str)); fos.write(str); fileOutputStream.close(); fos.close(); }
写出指定长度字节数组 通过 write(byte[] b, int off, int len) 方法,每次写出从 off 索引开始,len 个字节,代码使用演示:
1 2 3 4 5 6 7 8 9 10 11 12 public static void main (String[] args) throws IOException FileOutputStream fos = new FileOutputStream("F:\\home\\06.txt" ); byte [] b = "abcde" .getBytes(); fos.write(b, 2 , 2 ); fos.close(); }
数据追加续写 当我们创建输出流对象时,都会清空目标文件中的数据。那么如何保留目标文件中数据,并且还能继续添加新数据呢?使用以下两个构造方法便可以解决我们苦恼的问题。构造方法如下:
构造方法:
public FileOutputStream(File file, boolean append) : 创建文件输出流以写入由指定的 File 对象表示的文件。
public FileOutputStream(String name, boolean append) : 创建文件输出流以指定的名称写入文件。
这两个构造方法的参数中,都需要传入一个boolean 类型的值,true 表示追加数据,false 表示清空原有数据。这样创建的输出流对象,就可以指定是否追加续写了。代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 public static void main (String[] args) throws IOException FileOutputStream fos = new FileOutputStream("F:\\home\\05.txt" ,true ); byte [] bytes = "abcde" .getBytes(); fos.write(bytes); fos.close(); }
写出换行 Windows 系统里,换行符号是 \r\n ,代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static void main (String[] args) throws IOException FileOutputStream fos = new FileOutputStream("F:\\home\\05.txt" ); byte [] words = {97 , 98 , 99 , 100 , 101 }; for (int i = 0 ; i < words.length; i++) { fos.write(words[i]); fos.write("\r\n" .getBytes()); } fos.close(); }
回车符和换行符:
回车符:回到一行的开头(return)。
换行符:下一行(newline)。
各种系统的回车换行:
1、Windows 系统里,每行结尾是【回车 + 换行】 ,即 \r\n
2、Unix/Linux 系统里,每行结尾只有【换行】 ,即 \n
3、Mac 系统里,每行结尾是【回车】 ,即 \r 。从 Mac OS X 开始与 Linux 统一
字节输入流 java.io.InputStream 抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
基本共性功能方法:
public void close() :关闭此输入流并释放与此流相关联的任何系统资源。
public abstract int read(): 从输入流读取数据的下一个字节。
public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。
java.io.FileInputStream 类是文件输入流,从文件中读取字节。
读入数据的原理(硬盘-->内存):
java 程序 --> JVM --> OS --> OS读取数据的方法 --> 读取文件
字节输入流的使用步骤(重点) :
1、创建 FileInputStream 对象,构造方法中绑定要读取的数据源
2、使用 FileInputStream 对象中的方法 read , 读取文件
3、释放资源
构造方法
构造方法:
FileInputStream(File file) : 创建一个 FileInputStream ,该文件由文件系统中的 File 对象 file 命名。
FileInputStream(String name) : 创建一个 FileInputStream ,该文件由文件系统中的路径名 name 命名。
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有该文件,会抛出 FileNotFoundException 。构造举例,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 public static void main (String[] args) throws IOException File file = new File("F:\\home\\05.txt" ); FileInputStream fos = new FileInputStream(file); FileInputStream fileInputStream = new FileInputStream("F:\\home\\06.txt" ); fileInputStream.close(); fos.close(); }
读取字节数据 通过 read 方法,每次可以读取一个字节的数据,提升为 int 类型,读取到文件末尾,返回 -1 ,代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main (String[] args) throws Exception FileInputStream fileInputStream = new FileInputStream("F:\\home\\04.txt" ); int read = fileInputStream.read(); while (read != -1 ){ System.out.print(read + " " ); read = fileInputStream.read(); } fileInputStream.close(); }
小贴士:
1、虽然读取了一个字节,但是会自动提升为 int 类型。
使用字节数组读取 通过 read(byte[] b) ,每次读取 b 个字节到数组中,返回读取到的有效字节个数,读取到末尾时,返回 -1 ,代码使用演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public static void main (String[] args) throws IOException FileInputStream fis = new FileInputStream("F:\\home\\06.txt" ); int len; byte [] b = new byte [2 ]; while (( len = fis.read(b)) != -1 ) { System.out.println(new String(b)); } fis.close(); }
最后一次读取的 ed 是错误数据 ,原因是:在最后一次读取中,上次读取到的数据 c 被 e 替换了,而 d 没有被替换,只读取一个字节 e ,从而产生了错误。所以要通过 len 来获取有效的字节。代码使用演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public static void main (String[] args) throws IOException FileInputStream fis = new FileInputStream("F:\\home\\03.txt" ); int len; byte [] b = new byte [1024 ]; while ((len = fis.read(b)) != -1 ) { System.out.println(new String(b, 0 , len)); System.out.println(len); } fis.close(); }
小贴士: 使用数组读取,每次读取多个字节,减少了系统间的 IO 操作次数,从而提高了读写的效率,建议开发中使用。
图片复制练习 复制原理图解
案例实现 复制图片文件,代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static void main (String[] args) throws IOException FileInputStream fis = new FileInputStream("F:\\home\\01.png" ); FileOutputStream fos = new FileOutputStream("F:\\01.png" ); byte [] bytes = new byte [1024 * 8 ]; int len; while ((len = fis.read(bytes)) != -1 ) { fos.write(bytes, 0 , len); } fos.close(); fis.close(); }
小贴士: 流的关闭原则:先开后关,后开先关。
字符流 当使用字节流读取文本文件时,可能会有一个小问题。就是遇到中文字符时,可能不会显示完整的字符,那是因为一个中文字符可能占用多个字节存储。所以 Java 提供一些字符流类,以字符为单位读写数据,专门用于处理文本文件。
使用字节流读取中文文件,1个中文所占用字节如下:GBK: 占用 2 字节UTF-8: 占用 3 个字节
字符输入流 java.io.Reader 抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
基本共性功能方法:
public void close() :关闭此流并释放与此流相关联的任何系统资源。
public int read() : 从输入流读取一个字符。
public int read(char[] cbuf) : 从输入流中读取一些字符,并将它们存储到字符数组 cbuf 中 。
FileReader 类 java.io.FileReader 类是读取字符文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
小贴士:
1、字符编码: 字节与字符的对应规则。Windows 系统的中文编码默认是 GBK 编码表。在 IDEA 中是 UTF-8 编码。2、字节缓冲区: 一个字节数组,用来临时存储字节数据。
构造方法
构造方法:
FileReader(File file) : 创建一个新的 FileReader ,给定要读取的File对象。
FileReader(String fileName) : 创建一个新的 FileReader ,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径。类似于 FileInputStream 。构造举例,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 public static void main (String[] args) throws IOException File file = new File("F:\\home\\02.txt" ); FileReader fr = new FileReader(file); FileReader fileReader = new FileReader("F:\\home\\03.txt" ); fileReader.close(); fr.close(); }
读取字符数据 通过 read 方法,每次可以读取一个字符的数据,提升为 int 类型,读取到文件末尾,返回 -1 ,循环读取,代码使用演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) throws IOException FileReader fr = new FileReader("F:\\home\\02.txt" ); int b; while ((b = fr.read()) != -1 ) { System.out.println((char )b); } fr.close(); }
小贴士: 虽然读取了一个字符,但是会自动提升为 int 类型。
通过 read(char[] cbuf) 方法,每次读取 b 个字符到数组中,返回读取到的有效字符个数,读取到末尾时,返回 -1 ,代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void main (String[] args) throws IOException FileReader fr = new FileReader("F:\\home\\01.txt" ); char [] cs = new char [2 ]; int len; while ((len = fr.read(cs)) != -1 ){ System.out.println(new String(cs); } fr.close(); }
获取有效的字符改进,避免读取到无效的字符,代码使用演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void main (String[] args) throws IOException FileReader fr = new FileReader("F:\\home\\01.txt" ); char [] cs = new char [2 ]; int len; while ((len = fr.read(cs)) != -1 ){ System.out.println(new String(cs, 0 , len)); } fr.close(); }
字符输出流 java.io.Writer 抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。以下是字符输出流的基本共性功能方法。
基本共性功能方法:
void write(int c) ,写入单个字符。
void write(char[] cbuf) ,写入字符数组。
abstract void write(char[] cbuf, int off, int len) ,写入字符数组的某一部分,off数组的开始索引,len写的字符个数。
FileWriter 类 java.io.FileWriter 类是写出字符到文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
构造方法
构造方法:
FileWriter(File file) : 创建一个新的 FileWriter,给定要读取的 File 对象。
FileWriter(String fileName) : 创建一个新的 FileWriter,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径,类似于 FileOutputStream 。构造举例,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 public static void main (String[] args) throws IOException File file = new File("F:\\home\\05.txt" ); FileWriter fw = new FileWriter(file); FileWriter fileWriter = new FileWriter("F:\\home\\06.txt" ); fileWriter.close(); fw.close(); }
基本写出数据 通过 write(int b) 方法,每次可以写出一个字符数据,代码使用演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main (String[] args) throws IOException FileWriter fw = new FileWriter("F:\\home\\07.txt" ); fw.write(97 ); fw.write('b' ); fw.write('C' ); fw.write(30000 ); fw.close(); }
小贴士:
1、虽然参数为 int 类型四个字节,但是只会保留一个字符的信息写出。
关闭和刷新 因为内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要使用 flush() 方法了。代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static void main (String[] args) throws IOException FileWriter fw = new FileWriter("F:\\home\\08.txt" ); fw.write(97 ); fw.flush(); fw.write(98 ); fw.close(); fw.write(99 ); }
小贴士: 即便是 flush 方法写出了数据,操作的最后还是要调用 close 方法,释放系统资源。
写出其他数据 写出字符数组 :通过 write(char[] cbuf) 方法和 write(char[] cbuf, int off, int len) 方法 ,每次可以写出字符数组中的数据,用法类似于 FileOutputStream ,代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main (String[] args) throws IOException FileWriter fw = new FileWriter("F:\\home\\09.txt" ); char [] chars = "井冈山大学" .toCharArray(); fw.write(chars); fw.write(b, 3 , 2 ); fos.close(); }
写出字符串 :通过 write(String str) 方法和 write(String str, int off, int len) 方法,每次可以写出字符串中的数据,更为方便,代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main (String[] args) throws IOException FileWriter fw = new FileWriter("F:\\home\\10.txt" ); String msg = "井冈山大学" ; fw.write(msg); fw.write(msg, 3 , 2 ); fw.close(); }
数据追加续写 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void main (String[] args) throws IOException FileWriter fw = new FileWriter("F:\\home\\11.txt" ,true ); fw.write("井冈山" ); fw.write("\r\n" ); fw.write("大学" ); fw.close(); }
小贴士:
1、字符流只能操作文本文件,不能操作图片、视频等非文本文件。
IO 异常的处理 JDK7 前处理 之前的代码中,我们一直把异常抛出,而实际开发中并不能这样处理,而是建议使用 try...catch...finally 代码块处理异常部分,代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public static void main (String[] args) FileWriter fw = null ; try { fw = new FileWriter("F:\\home\\11.txt" , true ); for (int i = 0 ; i < 10 ; i++) { fw.write("HelloWorld " + i + "\r\n" ); } }catch (IOException e){ System.out.println(e); }finally { if (fw != null ){ try { fw.close(); } catch (IOException e) { e.printStackTrace(); } } } }
JDK7 的处理 还可以使用 JDK7 优化后的 try-with-resource 语句,该语句确保了每个资源在语句结束时关闭。所谓的资源(resource)是指在程序完成后,必须关闭的对象。代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public static void main (String[] args) try ( FileInputStream fis = new FileInputStream("F:\\home\\12.txt" ); FileOutputStream fos = new FileOutputStream("F:\\home\\13.txt" );){ int len = 0 ; while ((len = fis.read()) != -1 ){ fos.write(len); } }catch (IOException e){ System.out.println(e); } }
JDK9 的改进 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public static void main (String[] args) throws IOException FileInputStream fis = new FileInputStream("F:\\home\\14.txt" ); FileOutputStream fos = new FileOutputStream("F:\\home\\15.txt" ); try (fis; fos){ int len = 0 ; while ((len = fis.read()) != -1 ){ fos.write(len); } }catch (IOException e){ System.out.println(e); } }
Properties 属性集 属性集概述 java.util.Properties 继承于 Hashtable System.getProperties 方法就是返回一个 Properties
Properties 类 构造方法和其他方法
构造方法:
public Properties() : 创建一个空的属性列表。
其他方法:
public Object setProperty(String key, String value) : 保存一对属性。
public String getProperty(String key) :使用此属性列表中指定的键搜索属性值。
public Set stringPropertyNames() :所有键的名称的集合。
上述方法代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public static void main (String[] args) Properties prop = new Properties(); prop.setProperty("赵丽颖" , "168" ); prop.setProperty("迪丽热巴" , "165" ); prop.setProperty("古力娜扎" , "160" ); Set<String> set = prop.stringPropertyNames(); for (String key : set) { String value = prop.getProperty(key); System.out.println(key + " = " + value); } }
与流相关的方法 这是保存的方法,知识点都在代码的注释里面了,请看代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static void main (String[] args) throws IOException Properties prop = new Properties(); prop.setProperty("赵丽颖" , "168" ); prop.setProperty("迪丽热巴" , "165" ); prop.setProperty("古力娜扎" , "175" ); FileWriter fw = new FileWriter("F:\\home\\14.txt" ); prop.store(fw,"save my data" ); fw.close(); }
这是读取的方法,知识点都在代码的注释里面了,请看代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public static void main (String[] args) throws IOException Properties prop = new Properties(); prop.load(new FileReader("F:\\home\\14.txt" )); Set<String> set = prop.stringPropertyNames(); for (String key : set) { String value = prop.getProperty(key); System.out.println(key + " = " + value); } }
小贴士:文本中的数据,必须是键值对形式,可以使用空格、等号、冒号等符号分隔。
缓冲流
上面介绍了基本的一些流,作为 IO 流的入门。现在我们要见识一些更强大的流,比如能够高效读写的缓冲流、能够转换编码的转换流、能够持久化存储对象的序列化流等等。这些功能更为强大的流,都是在基本的流对象基础之上创建而来的,就像穿上铠甲的武士一样,相当于是对基本流对象的一种增强。
缓冲流概述 缓冲流,也叫高效流,是对 4 个基本的 FileXxx 流的增强。缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统 IO 操作的次数,从而提高读写的效率。以下是缓冲流的分类:
按照数据类型分类:
字节缓冲流:BufferedInputStream 和 BufferedOutputStream
字符缓冲流:BufferedReader 和 BufferedWriter
字节缓冲流 构造方法
构造方法:
public BufferedInputStream(InputStream in) :创建一个新的缓冲输入流。
public BufferedOutputStream(OutputStream out) : 创建一个新的缓冲输出流。
构造方法举例如下:
1 2 3 4 5 BufferedInputStream bis = new BufferedInputStream(new FileInputStream("F:\\home\\05.txt" )); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("F:\\home\\05.txt" ));
字节缓冲输出流 字节缓冲输出流【BufferedOutputStream】实际案例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public static void main (String[] args) throws IOException FileOutputStream fos = new FileOutputStream("F:\\home\\05.txt" ); BufferedOutputStream bos = new BufferedOutputStream(fos); bos.write("井冈山大学" .getBytes()); bos.flush(); bos.close(); }
字节缓冲输入流 字节缓冲输入流【BufferedInputStream】实际案例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public static void main (String[] args) throws IOException FileInputStream fis = new FileInputStream("F:\\home\\05.txt" ); BufferedInputStream bis = new BufferedInputStream(fis); byte [] bytes = new byte [1024 * 8 ]; int len; while ((len = bis.read(bytes)) != -1 ) { System.out.println(new String(bytes, 0 , len)); } bis.close(); }
效率测试 查询 API,缓冲流读写方法与基本的流是一致的。那我们通过复制大文件(229MB),来测试它的效率。
基本流的复制,代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void main (String[] args) long start = System.currentTimeMillis(); try ( FileInputStream fis = new FileInputStream("F:\\home\\01.pdf" ); FileOutputStream fos = new FileOutputStream("F:\\01.pdf" ) ) { int b; while ((b = fis.read()) != -1 ) { fos.write(b); } } catch (IOException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("普通流复制时间: " + (end - start) + " 毫秒" ); }
缓冲流的复制,代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void main (String[] args) long start = System.currentTimeMillis(); try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream("F:\\home\\01.pdf" )); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("F:\\01.pdf" )) ) { int b; while ((b = bis.read()) != -1 ) { bos.write(b); } } catch (IOException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("缓冲流复制时间: " + (end - start) + " 毫秒" ); }
那么如何做才能更快呢?答案是:使用数组的方式,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static void main (String[] args) long start = System.currentTimeMillis(); try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream("F:\\home\\01.pdf" )); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("F:\\02.pdf" )) ) { int len; byte [] bytes = new byte [8 * 1024 ]; while ((len = bis.read(bytes)) != -1 ) { bos.write(bytes, 0 , len); } } catch (IOException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("缓冲流使用数组复制时间: " + (end - start) + " 毫秒" ); }
字符缓冲流 构造方法
构造方法:
public BufferedReader(Reader in) :创建一个新的缓冲输入流。
public BufferedWriter(Writer out) : 创建一个新的缓冲输出流。
构造方法举例如下:
1 2 3 4 5 BufferedReader br = new BufferedReader(new FileReader("F:\\home\\05.txt" )); BufferedWriter bw = new BufferedWriter(new FileWriter("F:\\home\\05.txt" ));
特有方法 字符缓冲流的基本方法与普通字符流调用方式一致,不再阐述,我们来看它们具备的特有方法。
特有方法:
BufferedReader:public String readLine() : 读一行文字。
BufferedWriter:public void newLine() : 相当于换行分隔符,由系统属性定义符号。
public String readLine() 方法演示,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main (String[] args) throws IOException BufferedReader br = new BufferedReader(new FileReader("F:\\home\\05.txt" )); String line; while ((line = br.readLine()) != null ) { System.out.print(line); System.out.println("---" ); } br.close(); }
public void newLine() 方法演示,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void main (String[] args) throws IOException BufferedWriter bw = new BufferedWriter(new FileWriter("F:\\home\\edu.txt" )); bw.write("井冈山" ); bw.newLine(); bw.write("大学" ); bw.newLine(); bw.write("欢迎你" ); bw.newLine(); bw.close(); }
字符缓冲输出流 字符缓冲输出流【BufferedWriter】实际案例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public static void main (String[] args) throws IOException BufferedWriter bw = new BufferedWriter(new FileWriter("F:\\home\\edu.txt" )); for (int i = 0 ; i < 10 ; i++) { bw.write("井冈山大学~~~" ); bw.newLine(); } bw.flush(); bw.close(); }
字符缓冲输入流 字符缓冲输入流【BufferedReader】实际案例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void main (String[] args) throws IOException BufferedReader br = new BufferedReader(new FileReader("F:\\home\\05.txt" )); String line; while ((line = br.readLine()) != null ) { System.out.println(line); } br.close(); }
练习:文本排序 练习描述 请将下列文本信息恢复顺序。
1 2 3 4 5 6 7 8 9 3.侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必得裨补阙漏,有所广益。 8.愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。 4.将军向宠,性行淑均,晓畅军事,试用之于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。 2.宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。 1.先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。 9.今当远离,临表涕零,不知所言。 6.臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。 7.先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐付托不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。 5.亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。
案例分析
1、逐行读取文本信息。
2、解析文本信息到集合中。
3、遍历集合,按顺序,写出文本信息。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public static void main (String[] args) throws IOException HashMap<String, String> map = new HashMap<>(); BufferedReader br = new BufferedReader(new FileReader("F:\\home\\05.txt" )); BufferedWriter bw = new BufferedWriter(new FileWriter("F:\\05.txt" )); String line; while ((line = br.readLine()) != null ) { String[] arr = line.split("\\." ); map.put(arr[0 ], arr[1 ]); } for (String key : map.keySet()) { String value = map.get(key); line = key + "." + value; bw.write(line); bw.newLine(); } bw.close(); br.close(); }
转换流 字符编码和字符集 字符编码 计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为 编码 解码
各种概念:
编码 : 字符(我们能看懂的) --> 字节(我们看不懂的)
解码 : 字节(我们看不懂的) --> 字符(我们能看懂的)
字符编码【Character Encoding】 : 就是一套自然语言的字符与二进制数之间的对应规则。
编码表 : 生活中文字和计算机中二进制的对应规则
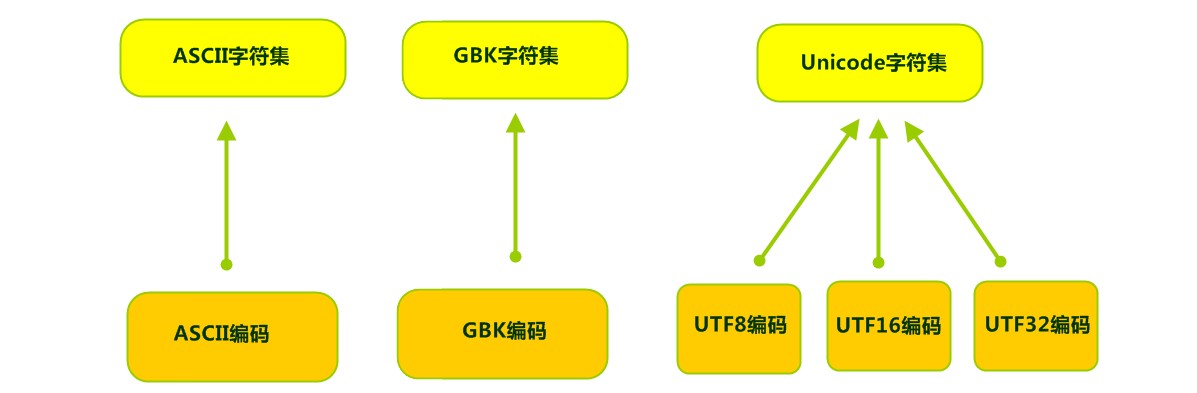
字符集 字符集【Charset】 ASCII 字符集 、GBK 字符集 、Unicode 字符 集等。字符编码与字符集对应关系如下图:
可见,当指定了 编码 字符集 编码
ASCII 字符集
1、 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
2、 基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
ISO-8859-1 字符集
拉丁码表,别名 Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。ISO-8859-1 使用单字节编码,兼容 ASCII 编码。
GBxxx 字符集
1、 GB 就是国标的意思,是为了显示中文而设计的一套字符集。
2、 GB2312 :简体中文码表。一个小于 127 的字符的意义与原来相同。但两个大于 127 的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
3、 GBK :最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
4、 GB18030 :最新的中文码表。收录汉字 70244 个,采用多字节编码,每个字可以由 1 个、2 个或 4 个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
Unicode字符集
1、 Unicode 编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。它最多使用 4 个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16 和 UTF-32。最为常用的 UTF-8 编码。
2、 UTF-8 编码,可以用来表示 Unicode 标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持 UTF-8 编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则如下:
1、 128 个 US-ASCII 字符,只需一个字节编码。
2、 拉丁文等字符,需要二个字节编码。
3、 大部分常用字(含中文),使用三个字节编码。
4、 其他极少使用的 Unicode 辅助字符,使用四字节编码。
编码引出的问题 在 IDEA 中,可以使用 FileReader 读取项目中的文本文件。由于 IDEA 默认是 UTF-8 编码,所以读取的内容没有任何问题。但是,当读取 Windows 系统中创建的文本文件时,由于 Windows 系统的默认是 GBK 编码,就会出现乱码。代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 public static void main (String[] args) throws IOException FileReader fileReader = new FileReader("F:\\GBK.txt" ); int read; while ((read = fileReader.read()) != -1 ) { System.out.print((char )read); } fileReader.close(); }
那么问题来了,我们要如何才能读取 GBK 编码的文件呢?这时就要用到转换流了。接着往下看 👇👇👇
转换流图解
转换流 java.io.InputStreamReader ,是 Reader 的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
构造方法
InputStreamReader(InputStream in) : 创建一个使用默认字符集的字符流。
InputStreamReader(InputStream in, String charsetName) : 创建一个指定字符集的字符流。
指定编码读取 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public static void main (String[] args) throws IOException read_gbk(); read_utf_8(); } private static void read_gbk () throws IOException InputStreamReader isr = new InputStreamReader(new FileInputStream("F:\\gbk.txt" ),"GBK" ); int len; while ((len = isr.read())!=-1 ){ System.out.println((char )len); } isr.close(); } private static void read_utf_8 () throws IOException InputStreamReader isr = new InputStreamReader(new FileInputStream("F:\\utf_8.txt" )); int len; while ((len = isr.read())!=-1 ){ System.out.println((char )len); } isr.close(); }
OutputStreamWriter 类 转换流 java.io.OutputStreamWriter ,是 Writer 的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
构造方法
OutputStreamWriter(OutputStream in) : 创建一个使用默认字符集的字符流。
OutputStreamWriter(OutputStream in, String charsetName) : 创建一个指定字符集的字符流。
指定编码写出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public static void main (String[] args) throws IOException gbk(); utf_8(); } private static void gbk () throws IOException OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("F:\\gbk.txt" ),"GBK" ); osw.write("你好" ); osw.flush(); osw.close(); } private static void utf_8 () throws IOException OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("F:\\utf_8.txt" ),"utf-8" ); osw.write("你好" ); osw.flush(); osw.close(); }
练习:转换文件编码 将 GBK 编码的文本文件,转换为 UTF-8 编码的文本文件。代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static void main (String[] args) throws IOException InputStreamReader isr = new InputStreamReader(new FileInputStream("F:\\GBK.txt" ),"GBK" ); OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("F:\\utf_8.txt" ),"UTF-8" ); int len; while ((len = isr.read()) != -1 ){ osw.write(len); } osw.close(); isr.close(); }
序列化流 Java 提供了一种对象 序列化 对象的数据 、对象的类型 和 对象中存储的属性 等信息。字节序列写出到文件之后,相当于文件中 持久保存 反序列化 对象的数据 、对象的类型 和 对象中存储的数据 信息,都可以用来在内存中创建对象。请看下图理解序列化:
ObjectOutputStream 类 java.io.ObjectOutputStream 类,将 Java 对象的原始数据类型写出到文件,实现对象的持久存储。
构造方法
构造方法
public ObjectOutputStream(OutputStream out) : 创建一个指定 OutputStream 的 ObjectOutputStream 。
序列化操作
一、对象要想序列化,必须满足两个条件:
1、该类必须实现 java.io.Serializable 接口,这是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出 NotSerializableException 。
2、该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用 transient 关键字修饰。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 public class Person implements Serializable private static final long serialVersionUID = 1L ; private String name; public int age; public Person () } public Person (String name, int age) this .name = name; this .age = age; } @Override public String toString () return "Person{" + "name='" + name + '\'' + ", age=" + age + '}' ; } public String getName () return name; } public void setName (String name) this .name = name; } public int getAge () return age; } public void setAge (int age) this .age = age; } }
二、写出对象方法:
通过 public final void writeObject (Object obj)` 方法,将指定的对象写出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void main (String[] args) throws IOException ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("F:\\person.txt" )); oos.writeObject(new Person("小美女" , 18 )); oos.close(); }
ObjectInputStream 反序列化流,将之前使用 ObjectOutputStream 序列化的原始数据恢复为对象。
构造方法
构造方法:
public ObjectInputStream(InputStream in) : 创建一个指定 InputStream 的 ObjectInputStream 。
反序列化操作一
反序列化操作一:
如果能找到一个对象的 class 文件,我们可以进行反序列化操作,调用 ObjectInputStream 读取对象的 public final Object readObject() 方法,读取一个对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) throws IOException, ClassNotFoundException ObjectInputStream ois = new ObjectInputStream(new FileInputStream("F:\\person.txt" )); Object o = ois.readObject(); ois.close(); System.out.println(o); Person p = (Person)o; System.out.println(p.getName() + p.getAge()); }
JVM 可以反序列化对象的条件:
它必须能够找到 class 文件的类,如果找不到该类的 class 文件,则会抛出一个 ClassNotFoundException 异常。
反序列化操作二 还有一种情况,当 JVM 反序列化对象时,能找到 class 文件,但是 class 文件在序列化对象之后发生了修改,那么反序列化操作也会失败,会抛出一个 InvalidClassException 异常。
InvalidClassException 原因如下:
1、该类的序列版本号与从流中读取的类描述符的版本号不匹配
2、该类包含未知数据类型
3、该类没有可访问的无参数构造方法
Serializable 接口给需要序列化的类,提供了一个序列版本号。该版本号的目的在于验证序列化的对象和对应类是否版本匹配。只要给上述 Person 类加入下面代码就可以防止该异常发生。代码如下:
1 2 private static final long serialVersionUID = 1L ;
练习:序列化集合
1、将存有多个自定义对象的集合序列化操作,保存到 list.txt 文件中。
2、反序列化 list.txt ,并遍历集合,打印对象信息。
案例分析
案例分析:
1、把若干学生对象 ,保存到集合中。
2、把集合序列化。
3、反序列化读取时,只需要读取一次,转换为集合类型。
4、遍历集合,可以打印所有的学生信息。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 public static void main (String[] args) throws IOException, ClassNotFoundException ArrayList<Person> list = new ArrayList<>(); list.add(new Person("张三" ,18 )); list.add(new Person("李四" ,19 )); list.add(new Person("王五" ,20 )); ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("F:\\list.txt" )); oos.writeObject(list); ObjectInputStream ois = new ObjectInputStream(new FileInputStream("F:\\list.txt" )); Object o = ois.readObject(); ArrayList<Person> list2 = (ArrayList<Person>)o; for (Person p : list2) { System.out.println(p); } ois.close(); oos.close(); } class Person implements Serializable private static final long serialVersionUID = 1L ; private String name; public int age; public Person () } public Person (String name, int age) this .name = name; this .age = age; } @Override public String toString () return "Person{" + "name='" + name + '\'' + ", age=" + age + '}' ; } public String getName () return name; } public void setName (String name) this .name = name; } public int getAge () return age; } public void setAge (int age) this .age = age; } }
打印流 打印流概述 平时我们在控制台打印输出,是调用 print 方法和 println 方法完成的,这两个方法都来自于 java.io.PrintStream 类,该类能够方便地打印各种数据类型的值,是一种便捷的输出方式。接下来我们介绍 PrintStream 类
PrintStream 类 构造方法
构造方法:
public PrintStream(String fileName) : 使用指定的文件名创建一个新的打印流。
改变打印流向 System.out 就是 PrintStream 类型的,只不过它的流向是系统规定的,打印在控制台上。不过,既然是流对象,我们就可以玩一个 “小把戏” ,改变它的流向。示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public static void main (String[] args) throws FileNotFoundException PrintStream ps = new PrintStream("F:\\print.txt" ); ps.write(97 ); ps.println(97 ); ps.println(8.8 ); ps.println('a' ); ps.println("HelloWorld" ); ps.println(true ); ps.close(); }
示例代码二如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) throws FileNotFoundException System.out.println("我是在控制台输出" ); PrintStream ps = new PrintStream("F:\\print-out.txt" ); System.setOut(ps); System.out.println("我在打印流的目的地中输出" ); ps.close(); }
Java 中的 IO 流到此结束了,欢迎评论区留言!!!