

数据库的基本概念
数据库初识
数据库 就是用于存储和管理数据的仓库,它的英文单词: DataBase ,简称 : DB 。数据库本质上是一个文件系统,还是以文件的方式存在服务器的电脑上的。所有的关系型数据库都可以使用通用的 SQL 语句进行管理 ,即我们常说的 数据库管理系统 DBMS 【DataBase Management System】
数据库的特点
常见数据库
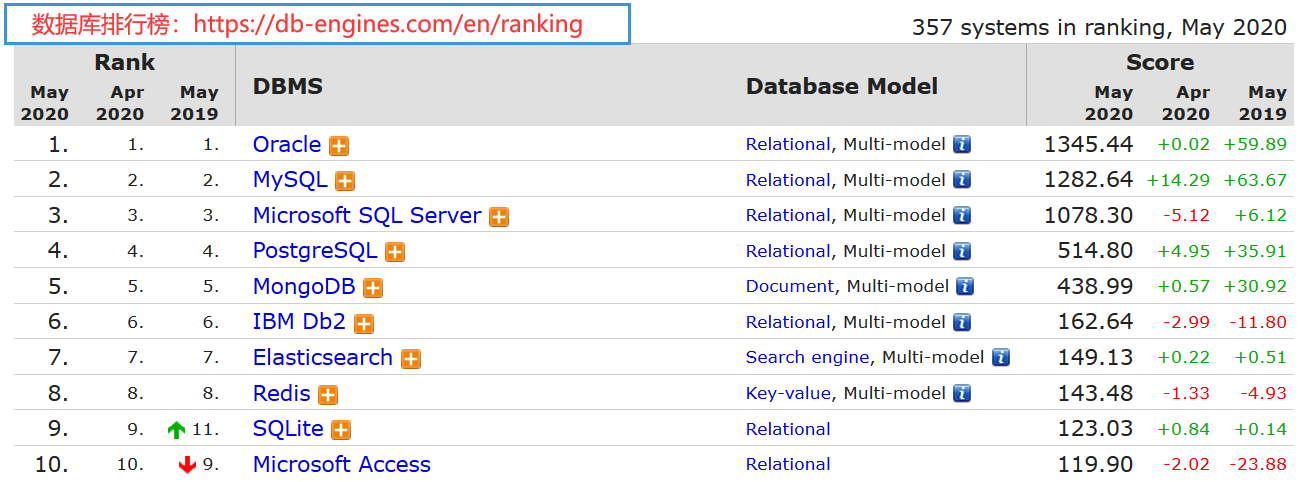
数据库排行榜
MySQL 数据库

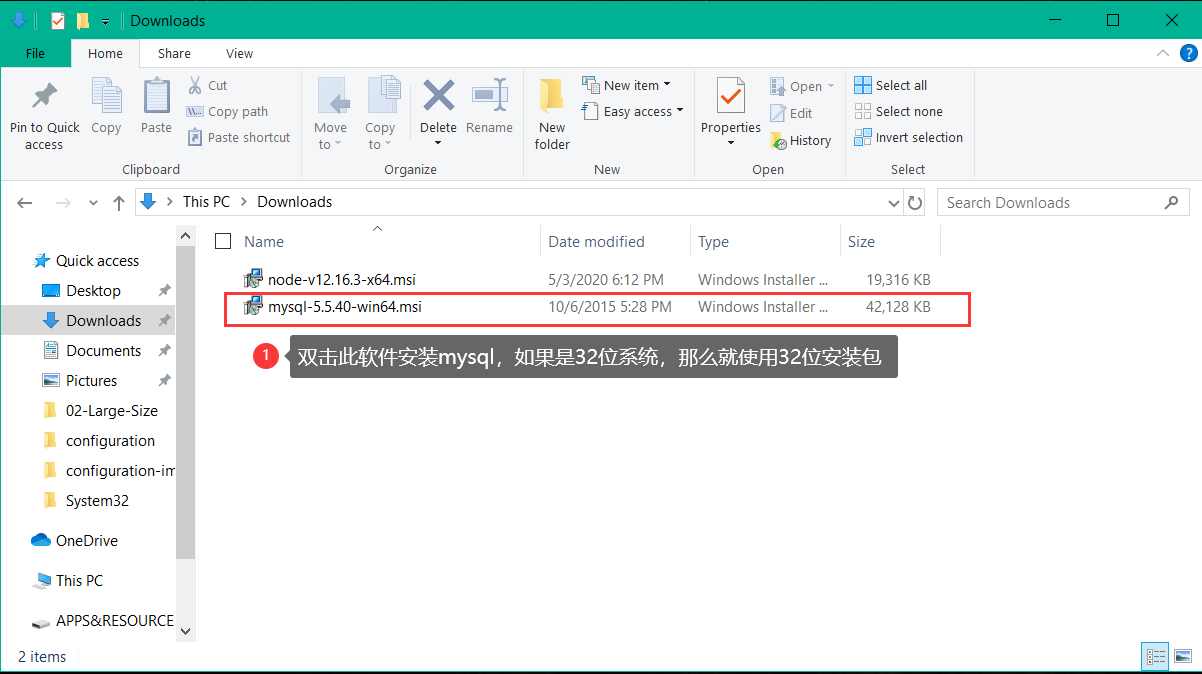
MySQL 安装
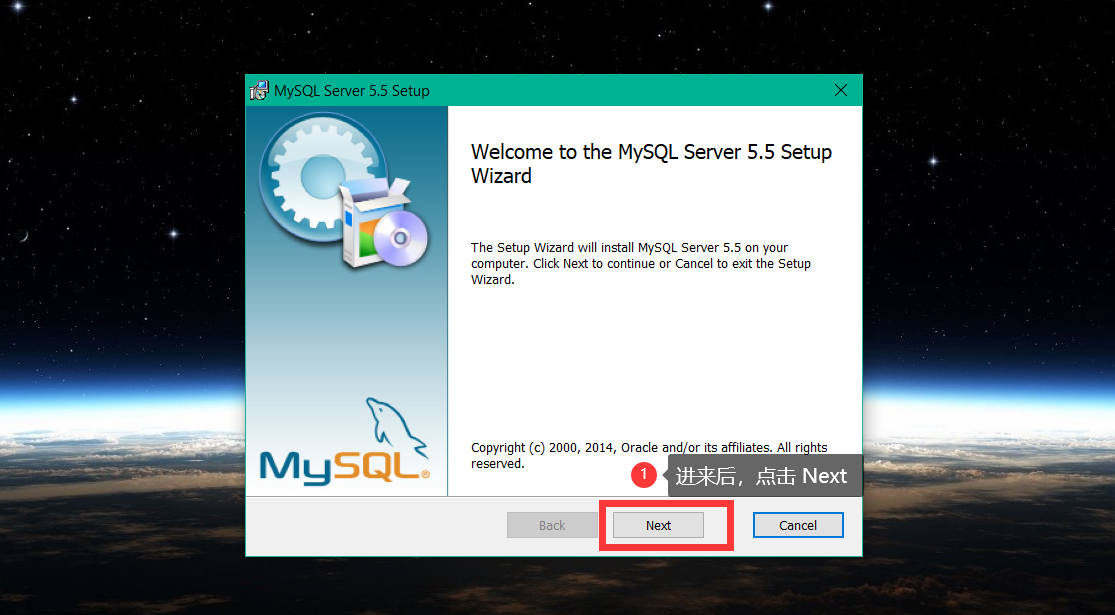
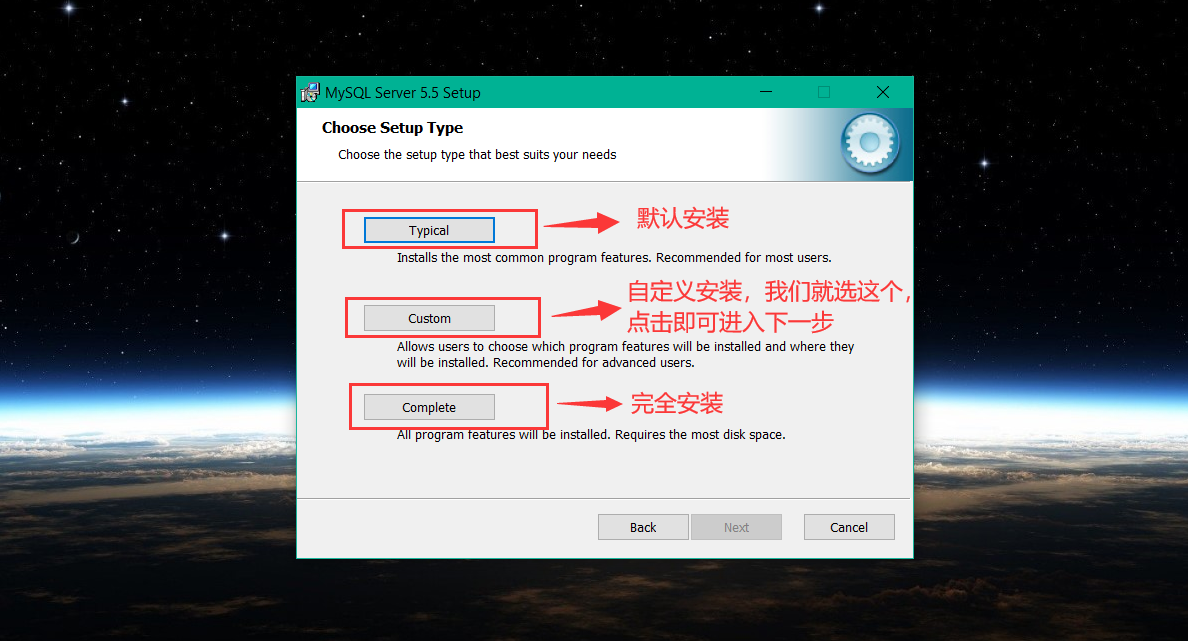
以下将 以图的方式 简述 MySQL 安装过程,如下:

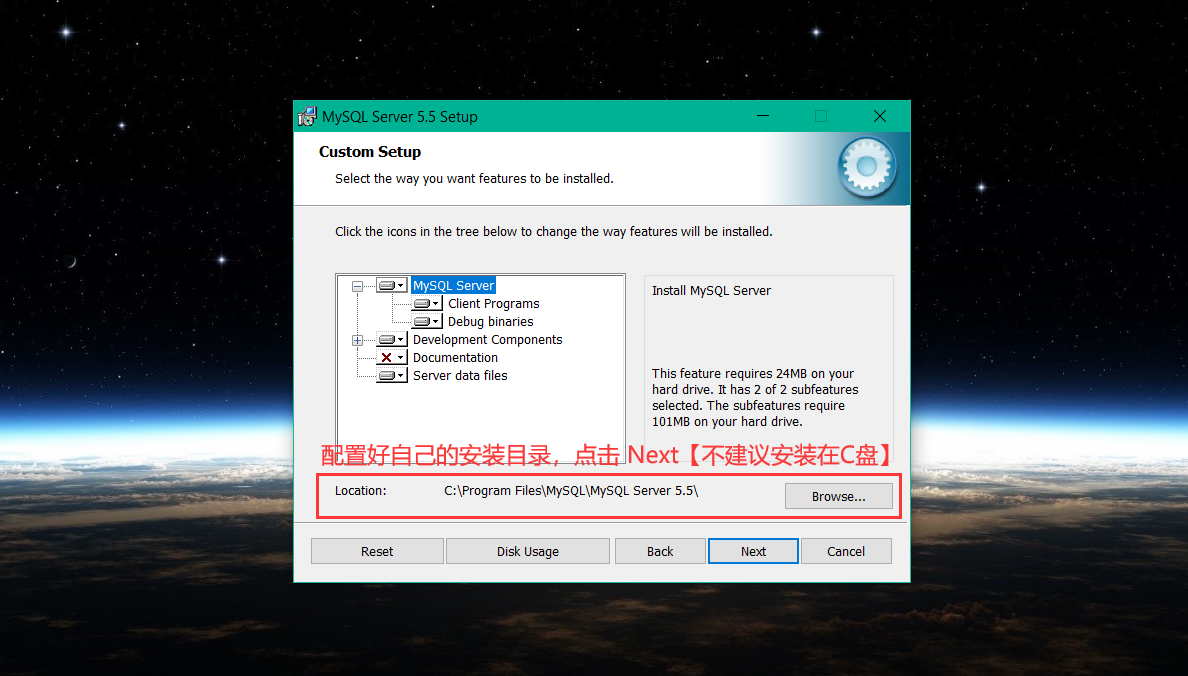


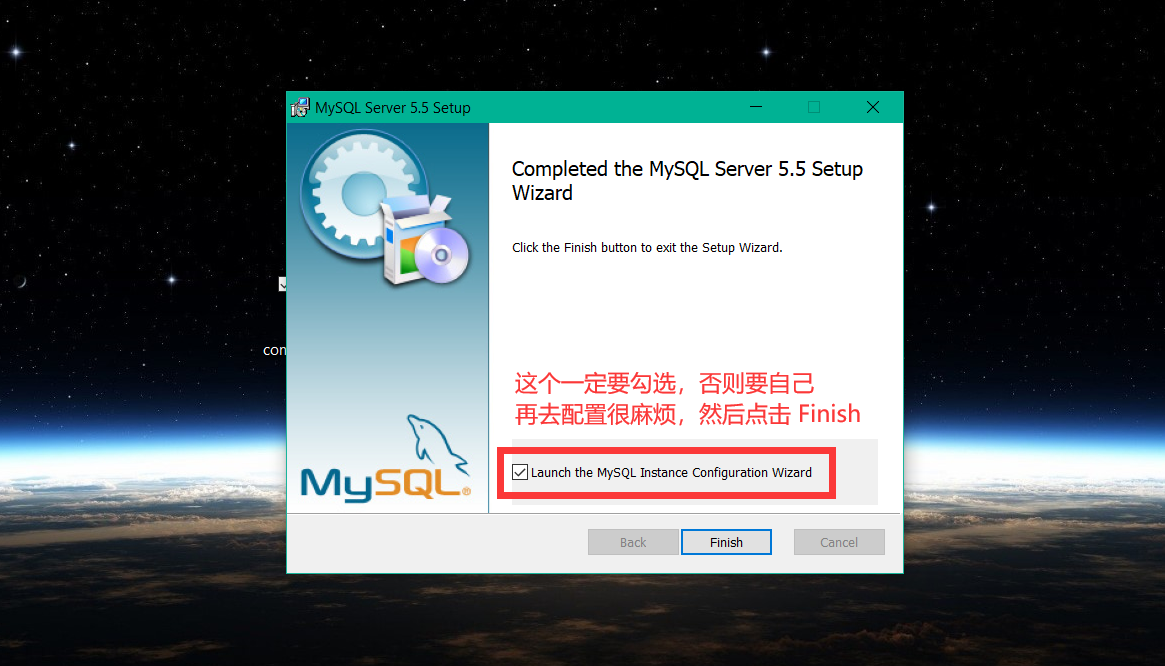

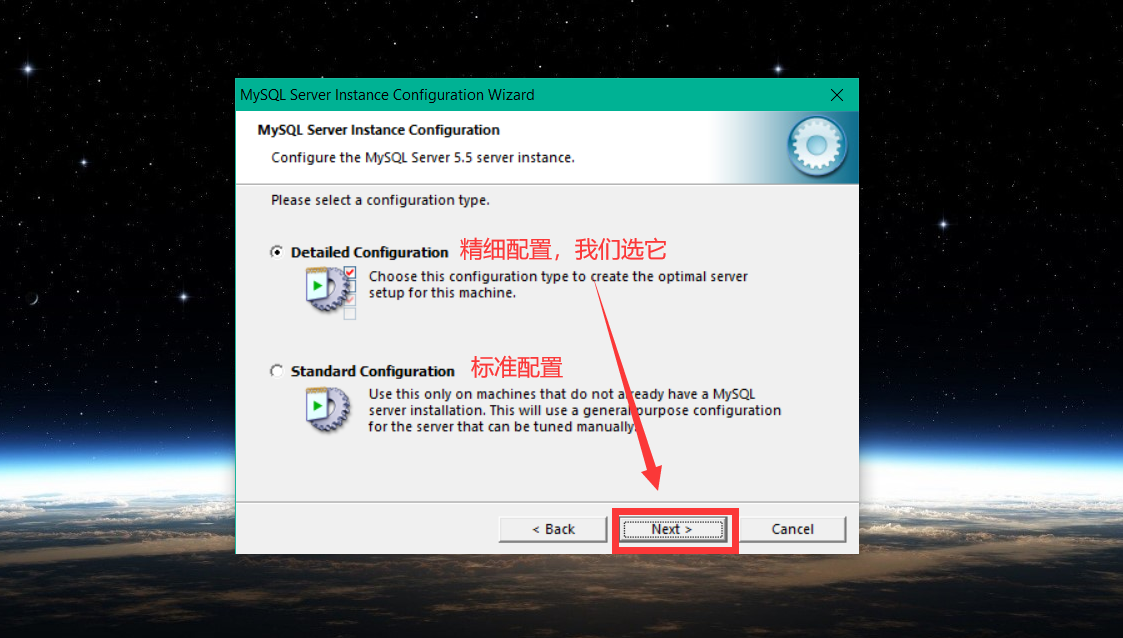
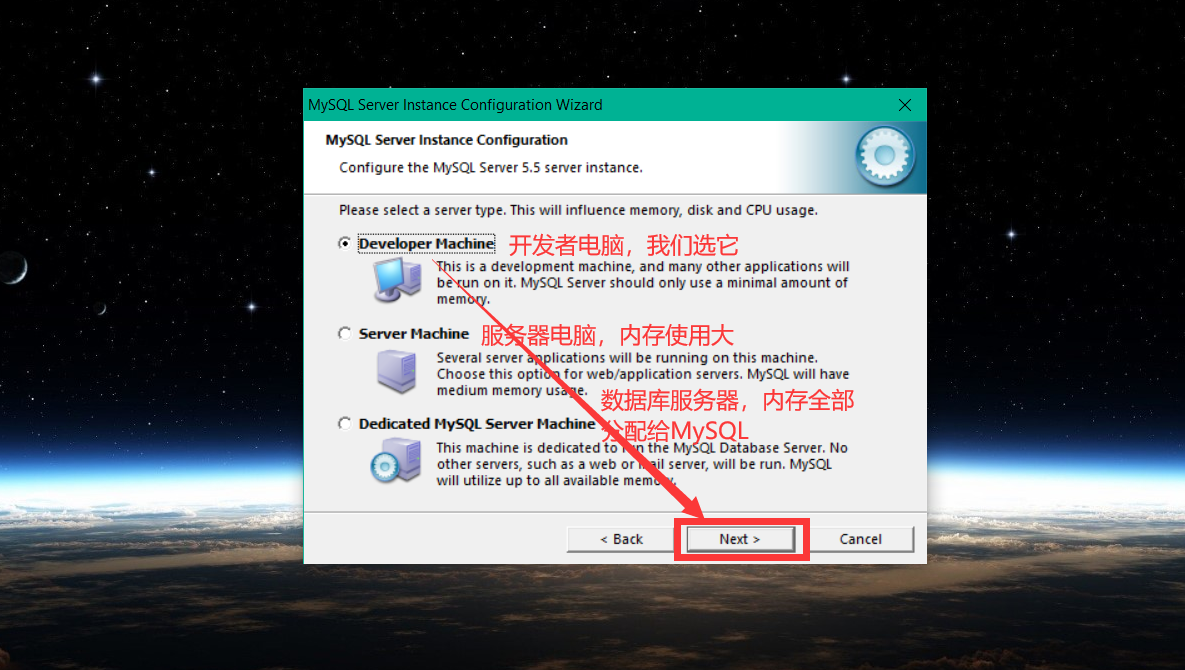

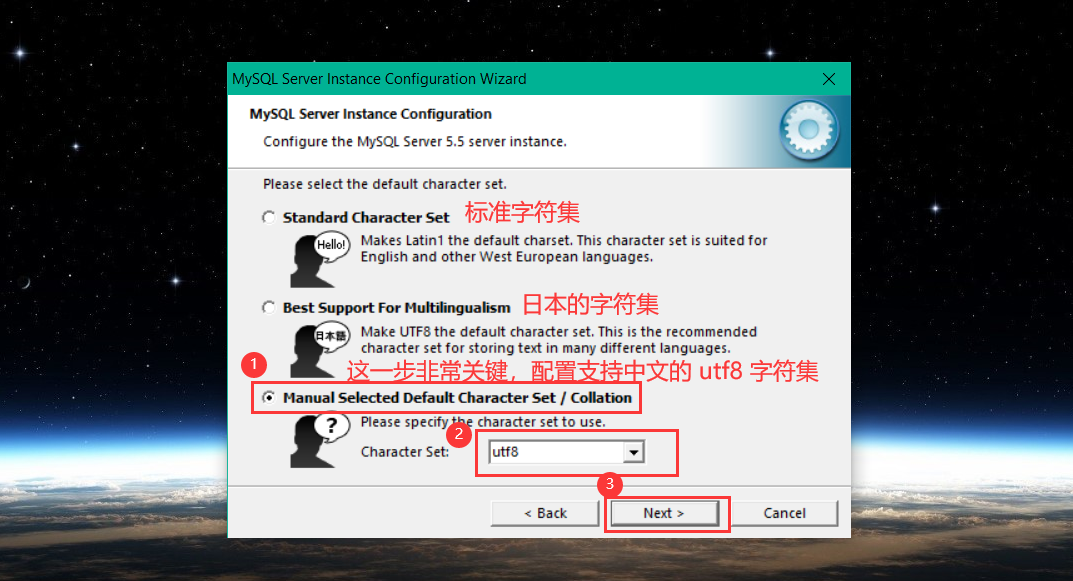

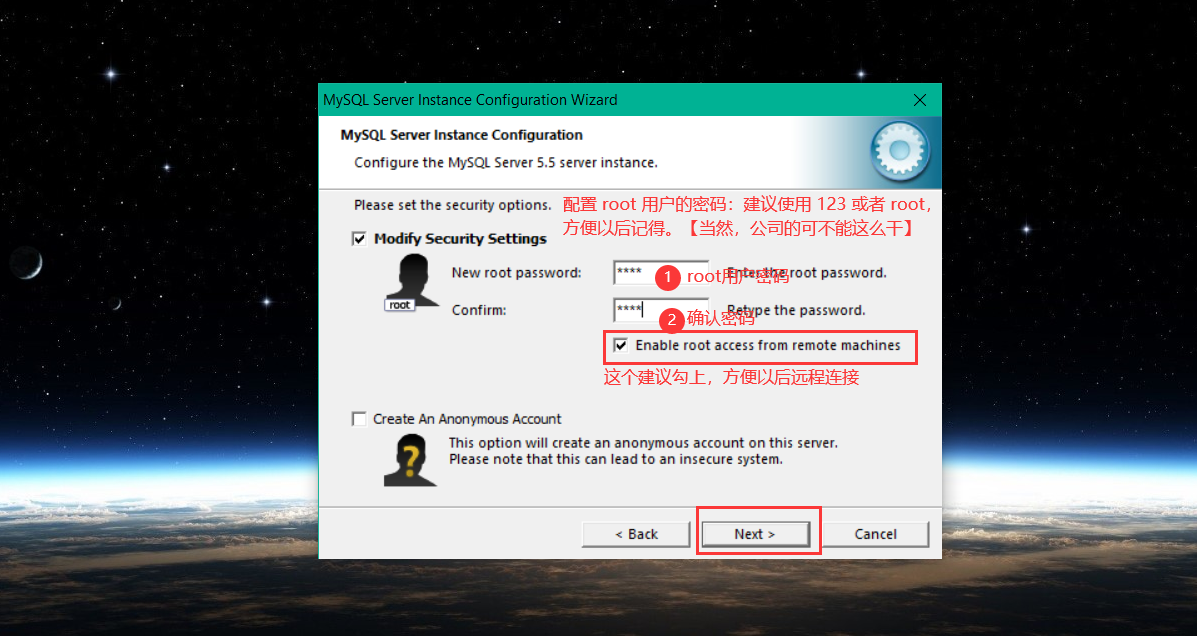


进入命令行 ,测试 MySQL 是否安装成功:
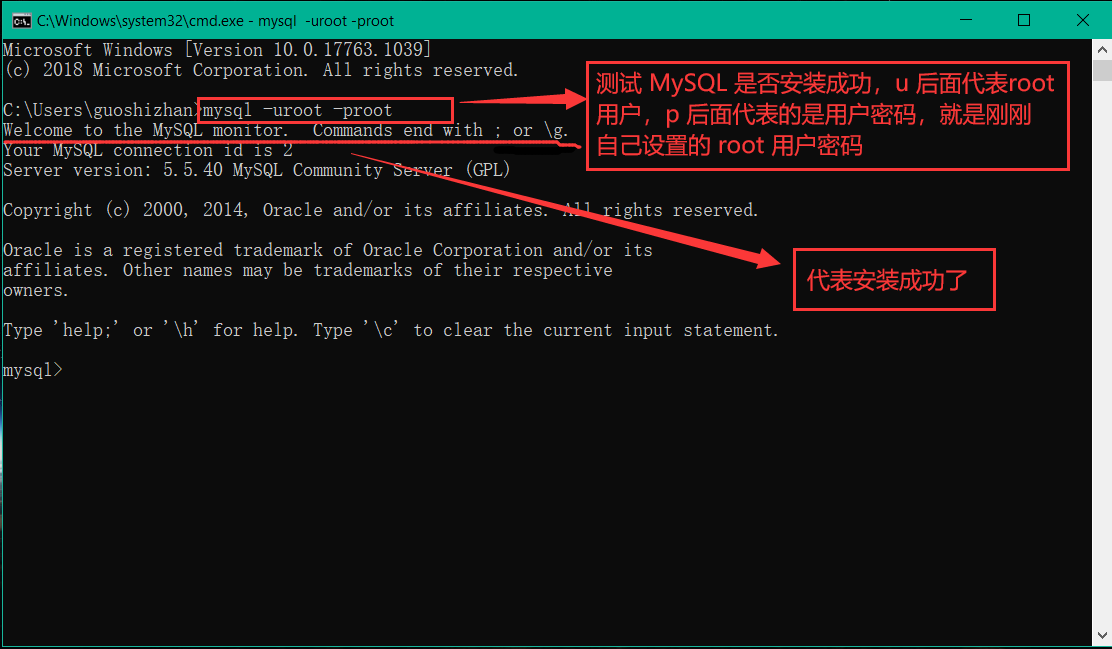
MySQL 卸载
有时候我们安装 MySQL 不成功,这个时候就要卸载 MySQL。但是,如果卸载不干净,那么再次安装 MySQL 的成功概率就特别低了,甚至就再也不能成功安装了。所以需要学会卸载 MySQL。话不多说,卸载步骤走起。第一步: 找到 MySQL 安装目录,打开 my.ini 文件:
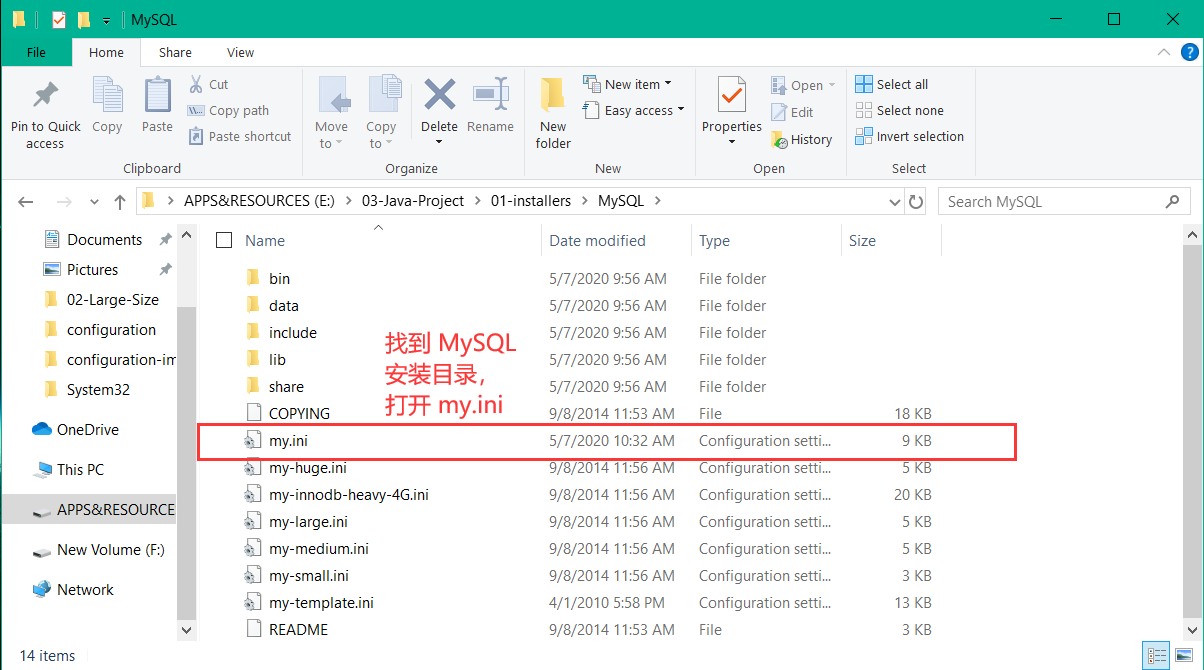
第二步: 使用 CTRL + F 查找 datadir ,找到的结果就是 MySQL 的数据存放目录,如果不出意外,大家结果都是一样的。找到之后复制出来,后面会用到这个目录。我的查找结果如下:
1 | #Path to the database root |
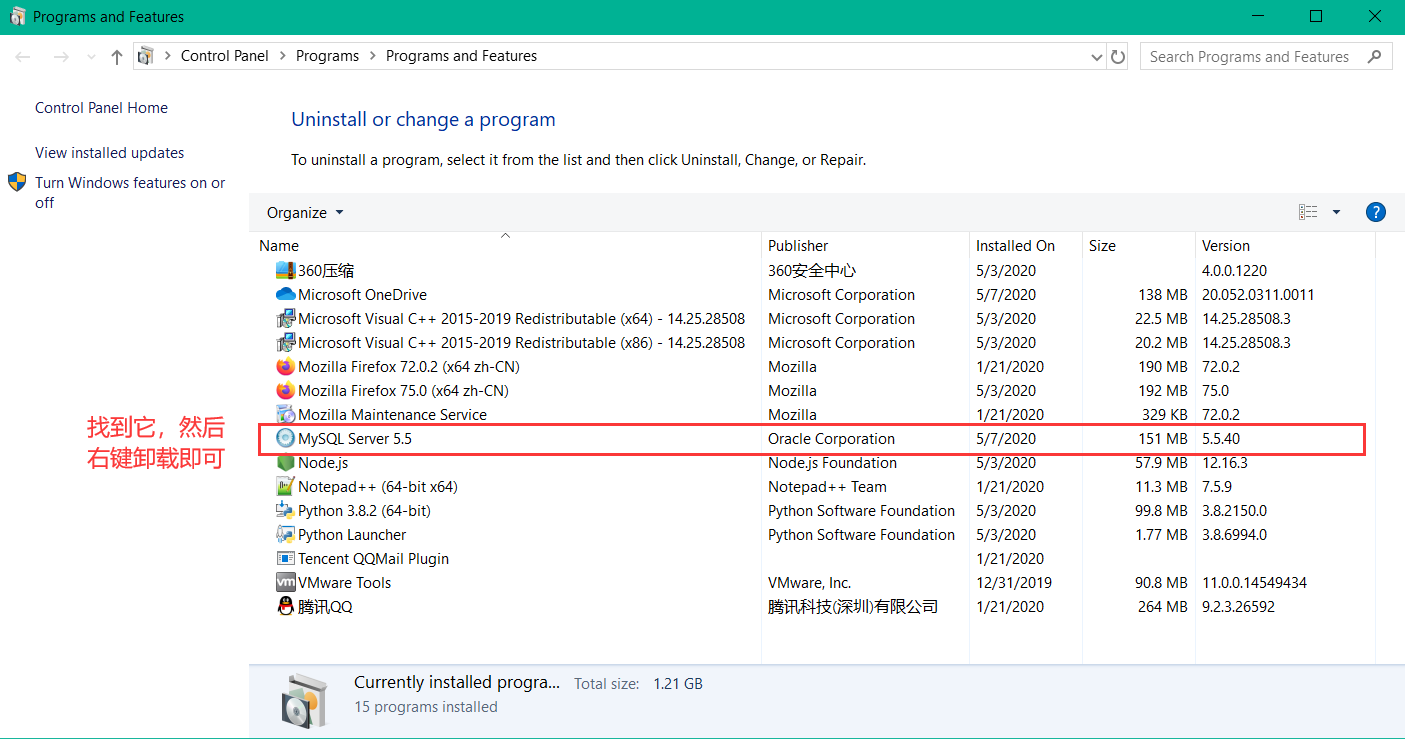
第三步: win + r ,然后输入 appwiz.cpl 打开应用控制面板,找到 MySQL ,然后卸载,如下图:
第四步: 当我们卸载了 MySQL 之后,其实并没有卸载干净。这时就要用到 第二步 查找到的那个目录的路径。我们截取此目录路径的一部分: C:/ProgramData ,然后打开这个目录,如下图:
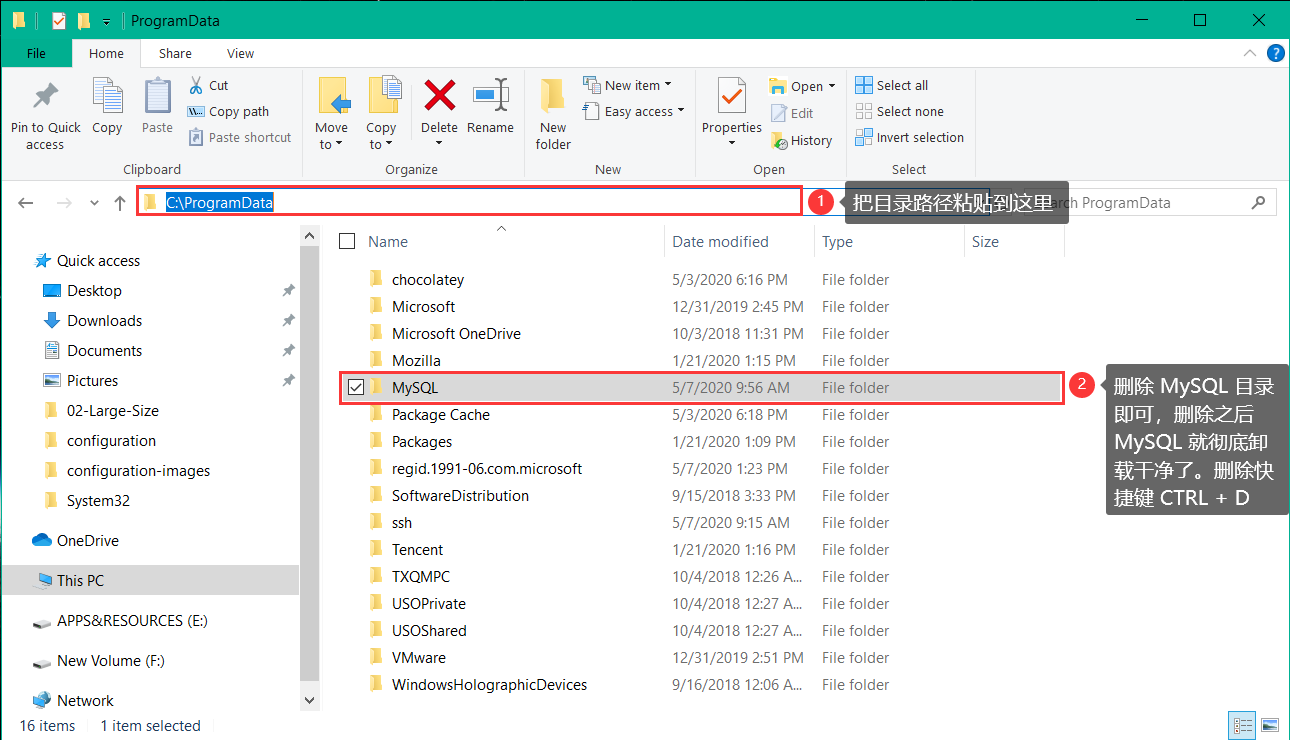
到这里为止,MySQL 的安装卸载 就搞定了。
MySQL 服务启动和关闭
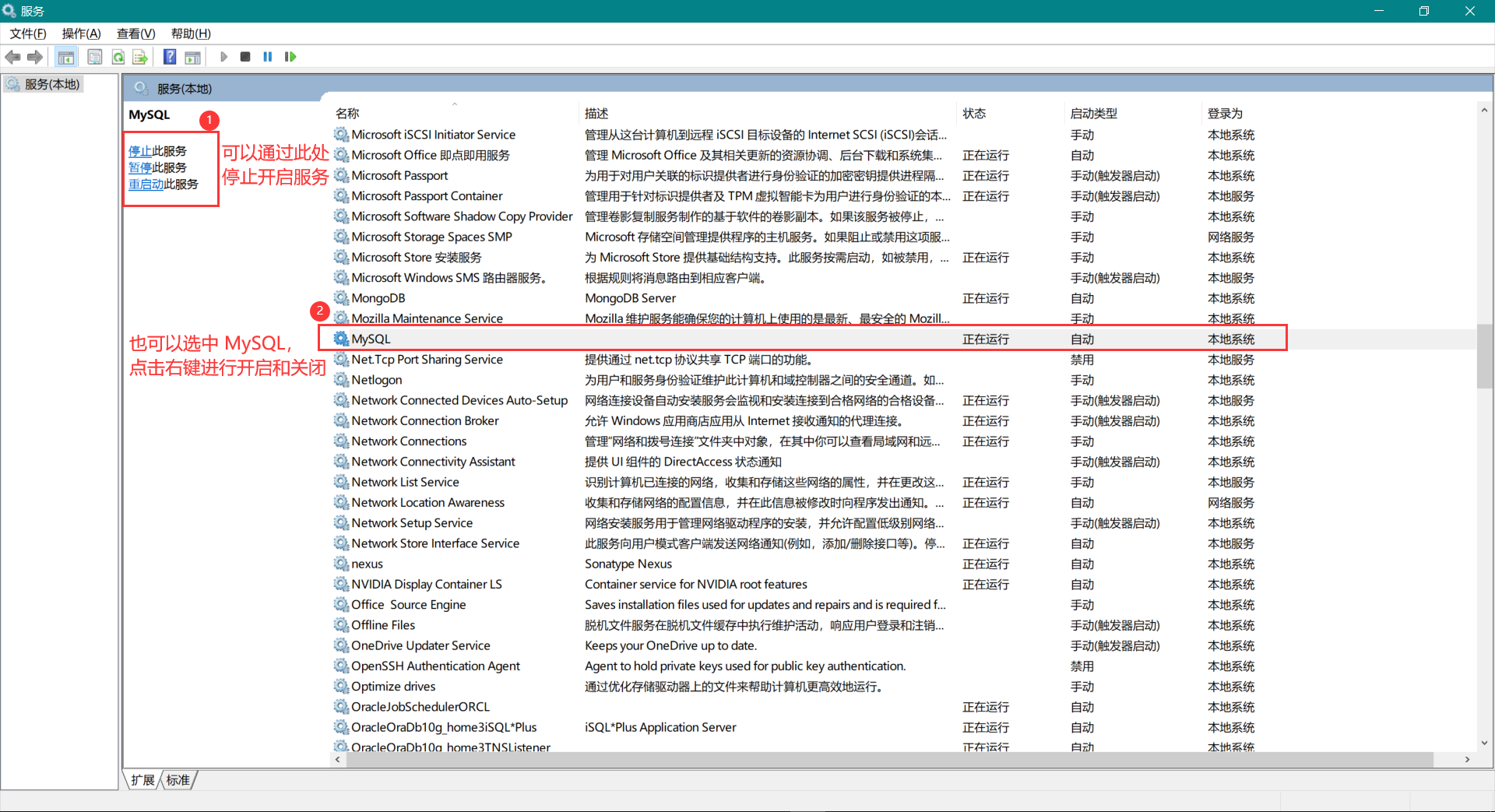
图形界面方式: 打开命令行 win + r ,然后输入 services.msc 进入到服务,如下图:
命令行方式: 打开命令行 win + r ,然后输入 net stop mysql 关闭 MySQL 服务,如下图:
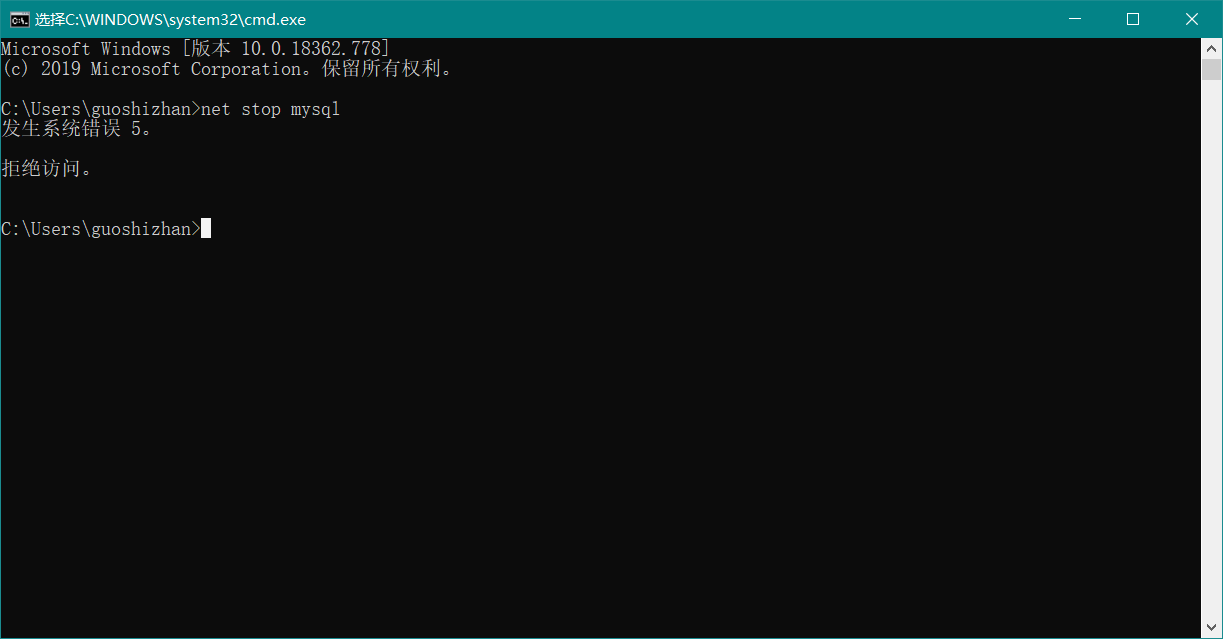
哎,发现不行呀。对的,这是权限不足问题。现在我们以 管理员身份 运行 net stop mysql 试试吧。如下图:
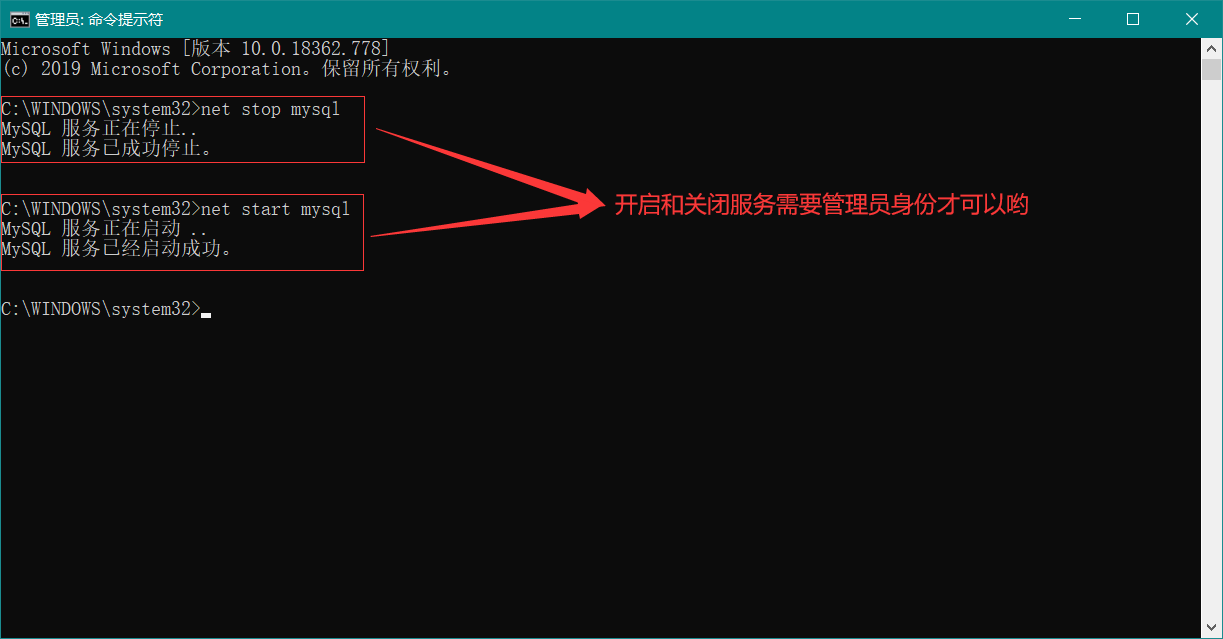
MySQL 登陆和退出
命令行方式: 打开命令行 win + r ,然后输入 cmd 进入到命令行,相关操作如下图:
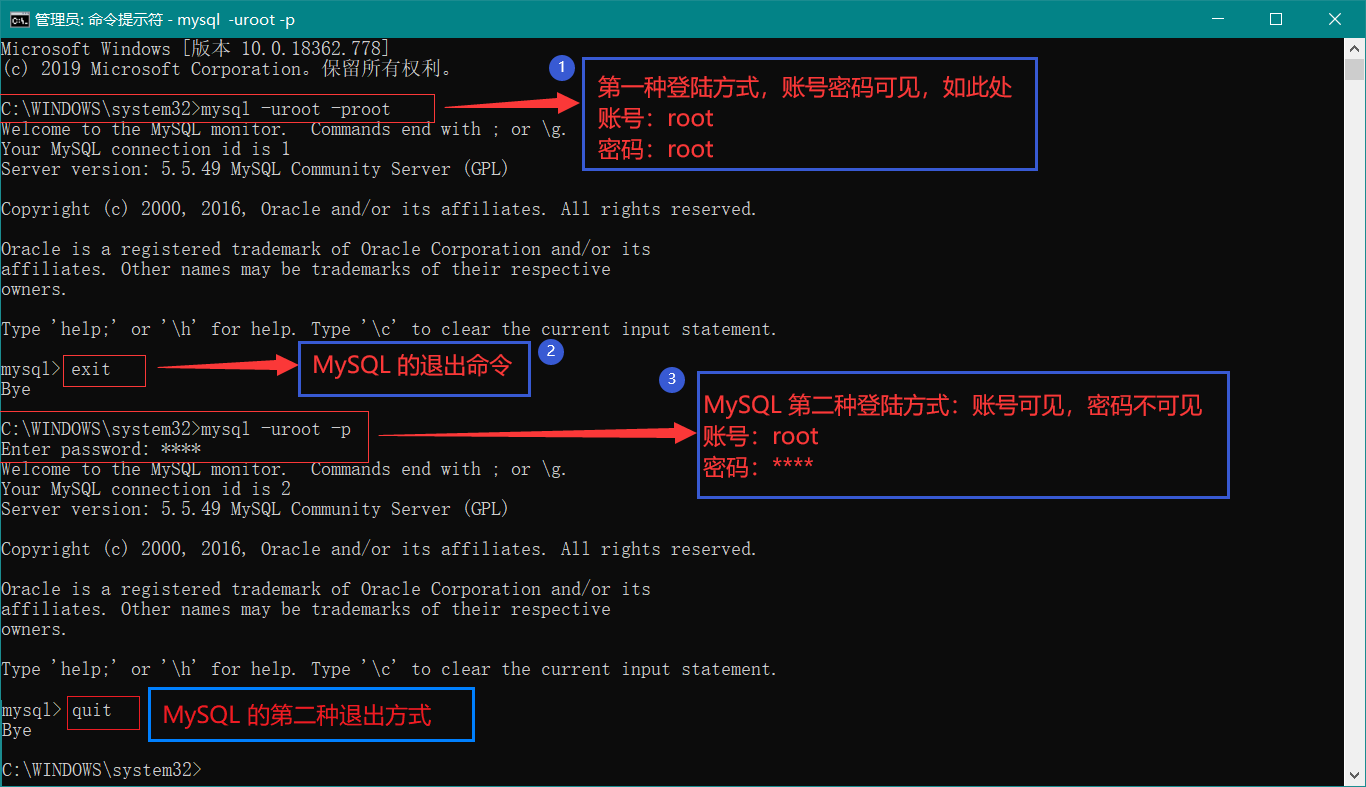
还记得我们安装 MySQL 设置密码的时候,那里勾选了远程连接,用来连接到远程的数据库。现在来讲解一下。举个例子:比如我要连接到我云服务器的 MySQL ,咋弄? 来,这么办,演示如下图:

MySQL 目录结构

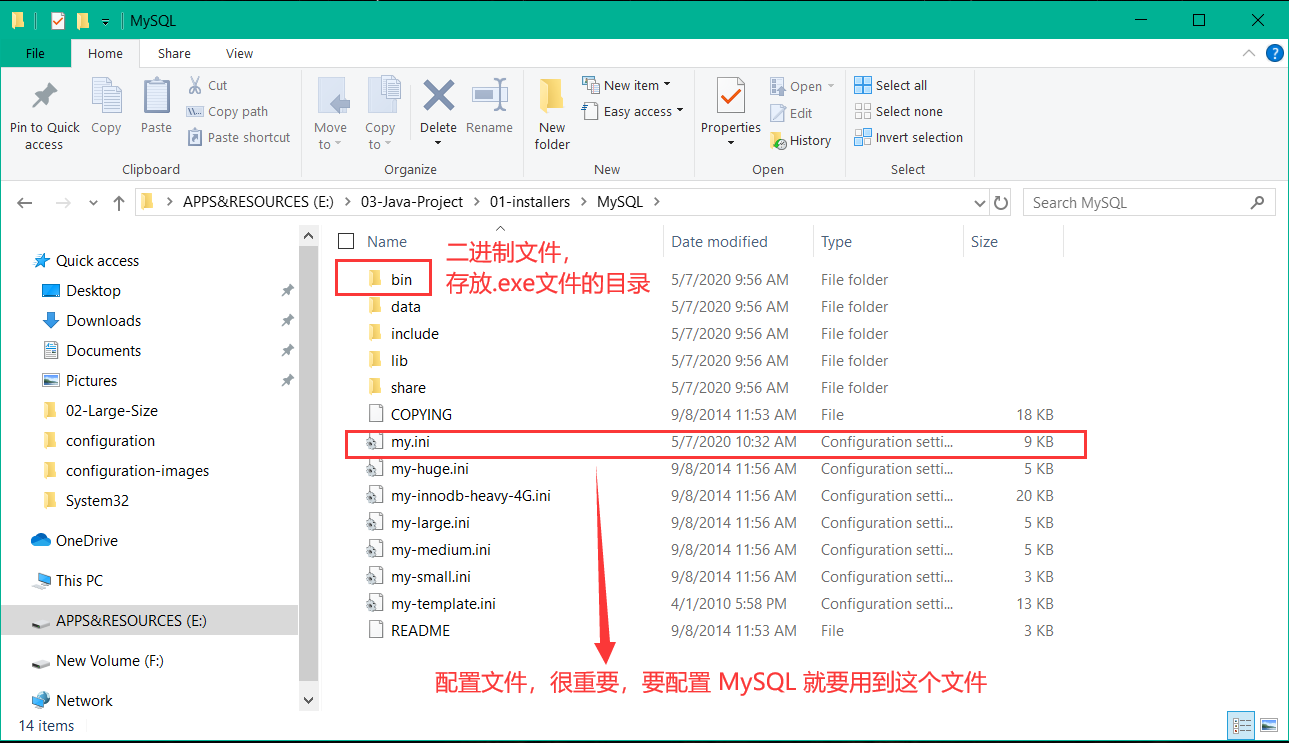
MySQL 的安装目录
MySQL 的安装目录其实就是 MySQL 的安装位置 ,这个目录里面的文件我们简单介绍一下:
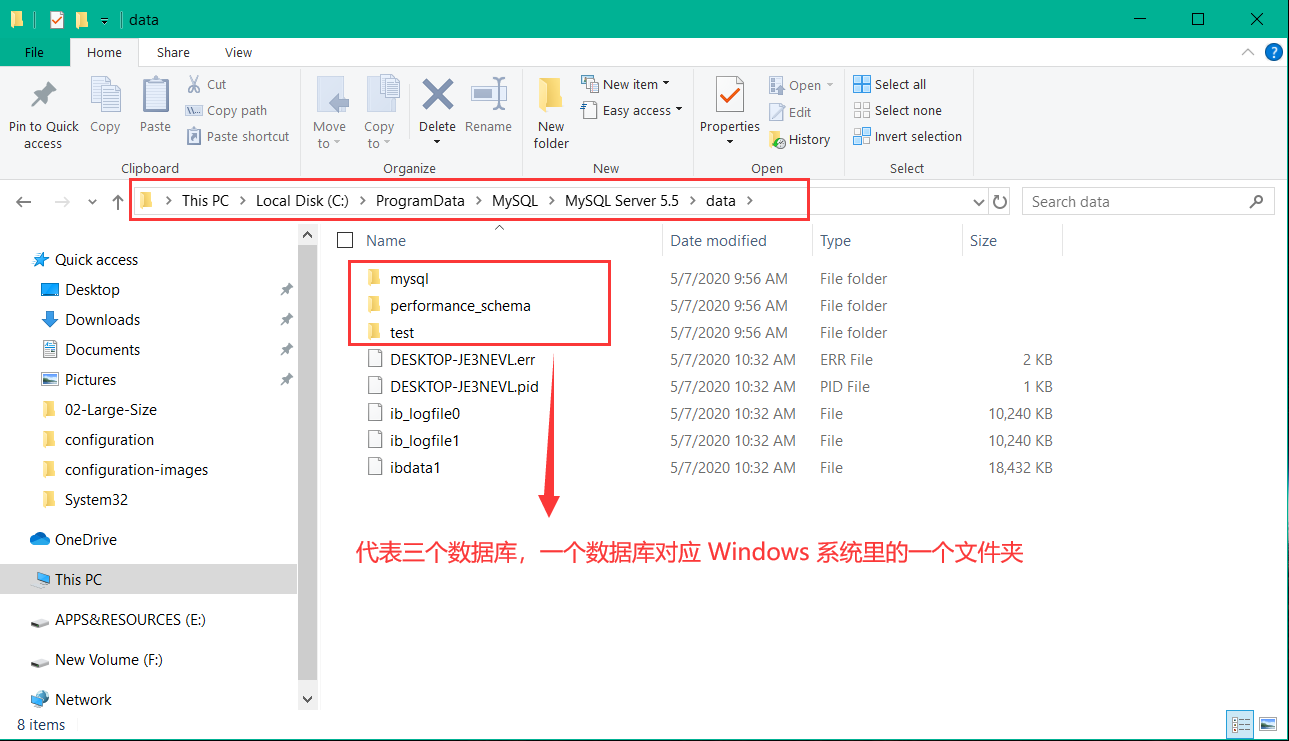
MySQL 的数据目录
SQL 初识
什么是 SQL
结构化查询语言(Structured Query Language) 简称 SQL ,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。【————百度百科】 SQL 的 作用 其实就是 定义了操作所有关系型数据库的规则 。但是每一种数据库操作的方式存在不一样的地方,称为 “方言” 。
SQL 通用语法
1 | select * from user; -- 单行注释 |
SQL 分类
我将以图的方式对下述 四种 SQL 分类 进行介绍,请看下图:
SQL-小白命令
1 | /* |
DDL-数据定义语言
DDL 概念: 数据定义语言【DDL】是 (Data Definition Language) 的缩写形式。用来定义和操作数据库对象。例如:数据库,表,列等。相关关键字: create , drop , alter 等。
安装完 MySQL 后,系统自带了 4 个数据库。都代表什么呢。相关的介绍如下图:

接下来介绍 创建数据库 和 指定字符集 (指定字符集的命令在 SQL-小白命令 处)相关的操作,如下图:
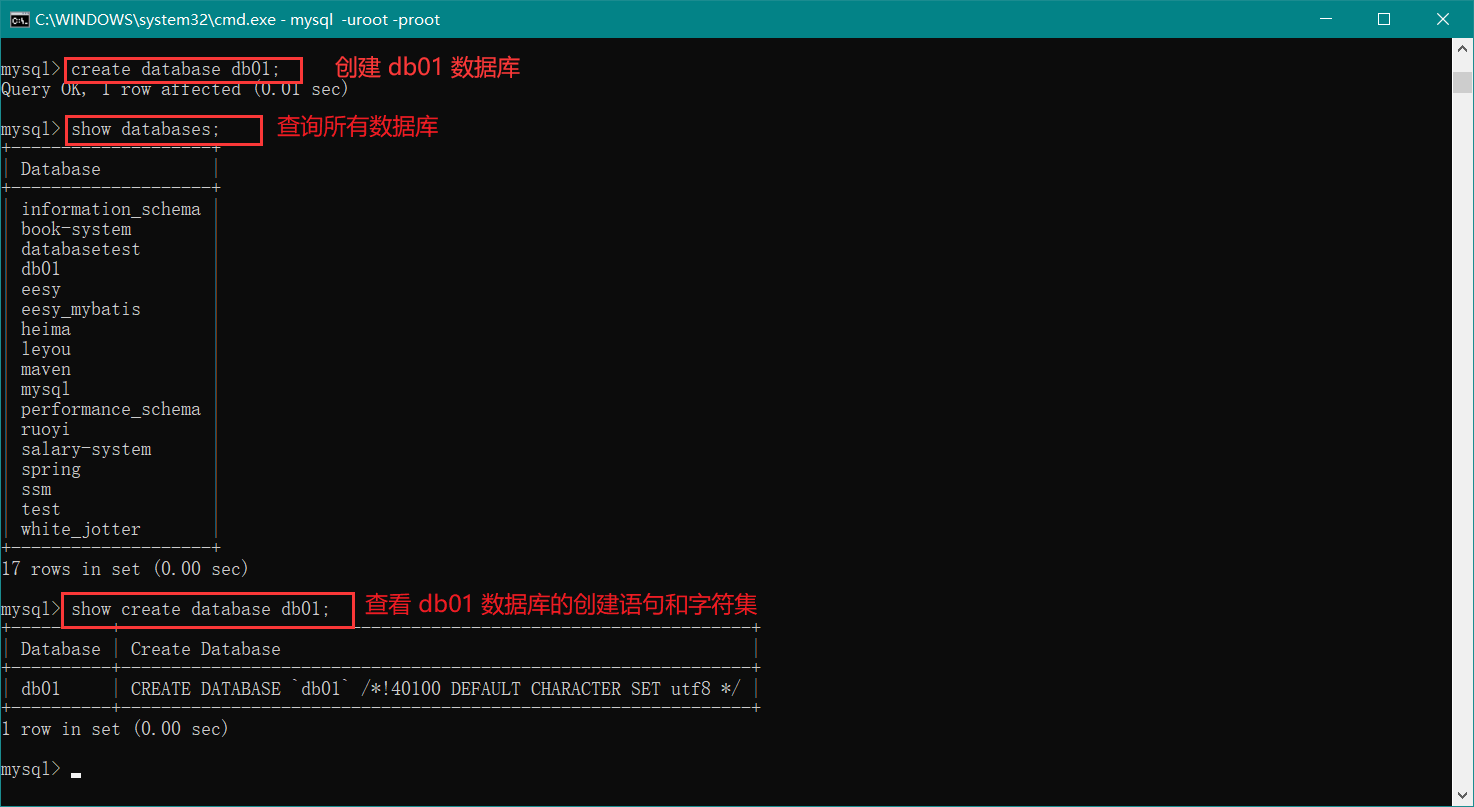
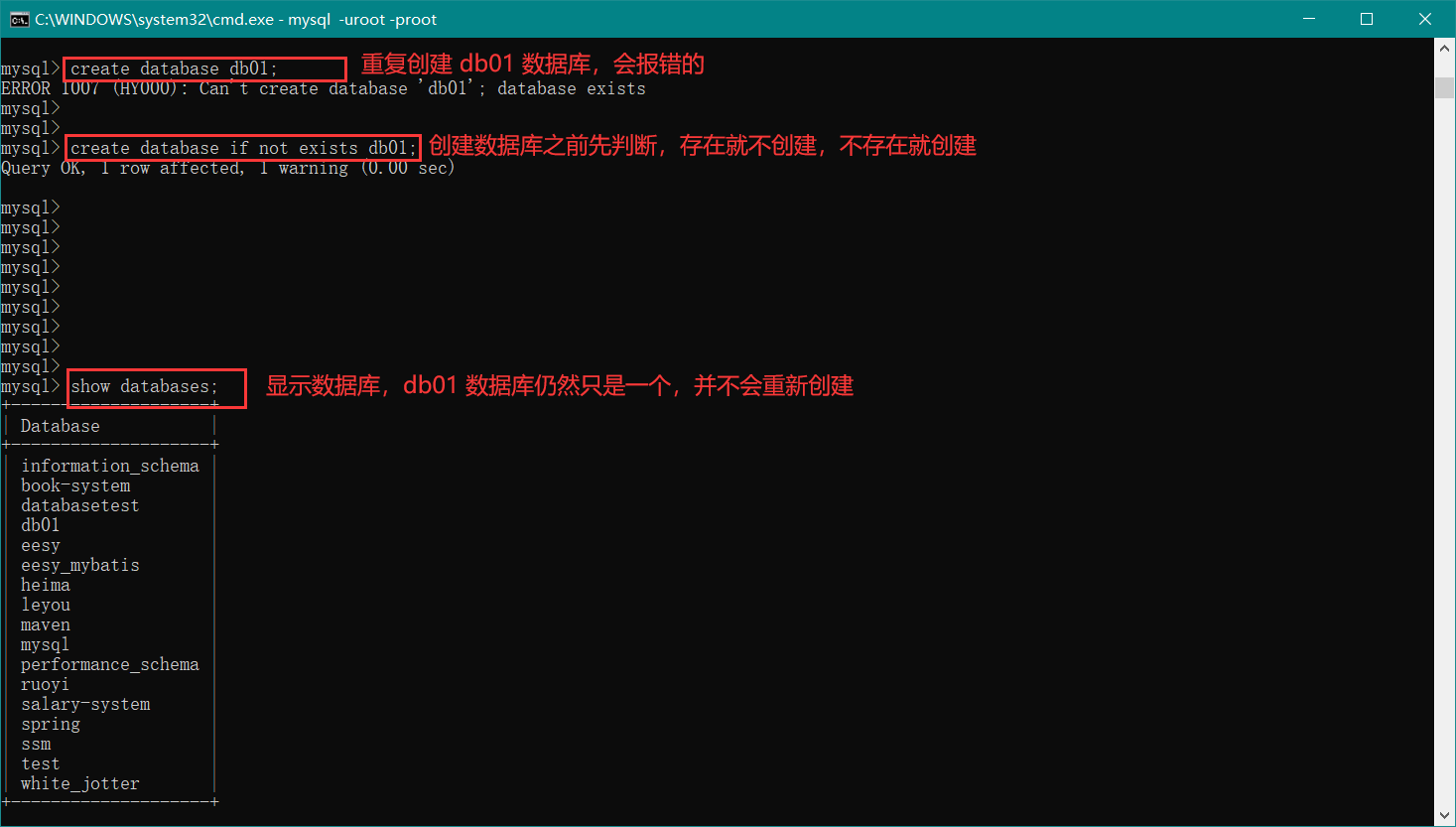
操作数据库的其他命令就不再一个一个地演示了,详情看上方的
SQL 命令汇总自行练习。接下来介绍 DDL 命令操作数据表 。
接着我们介绍 创建数据表和查询数据表 操作,首先认识 SQL 的数据类型,如下图:
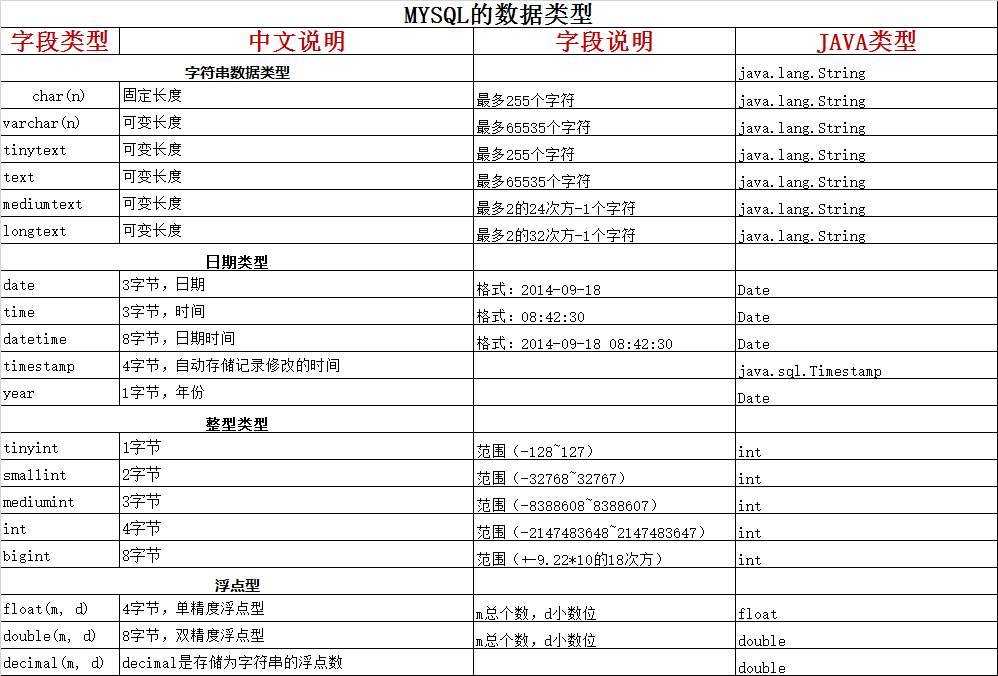
接下来我们 创建表和查询表 ,操作如下图:
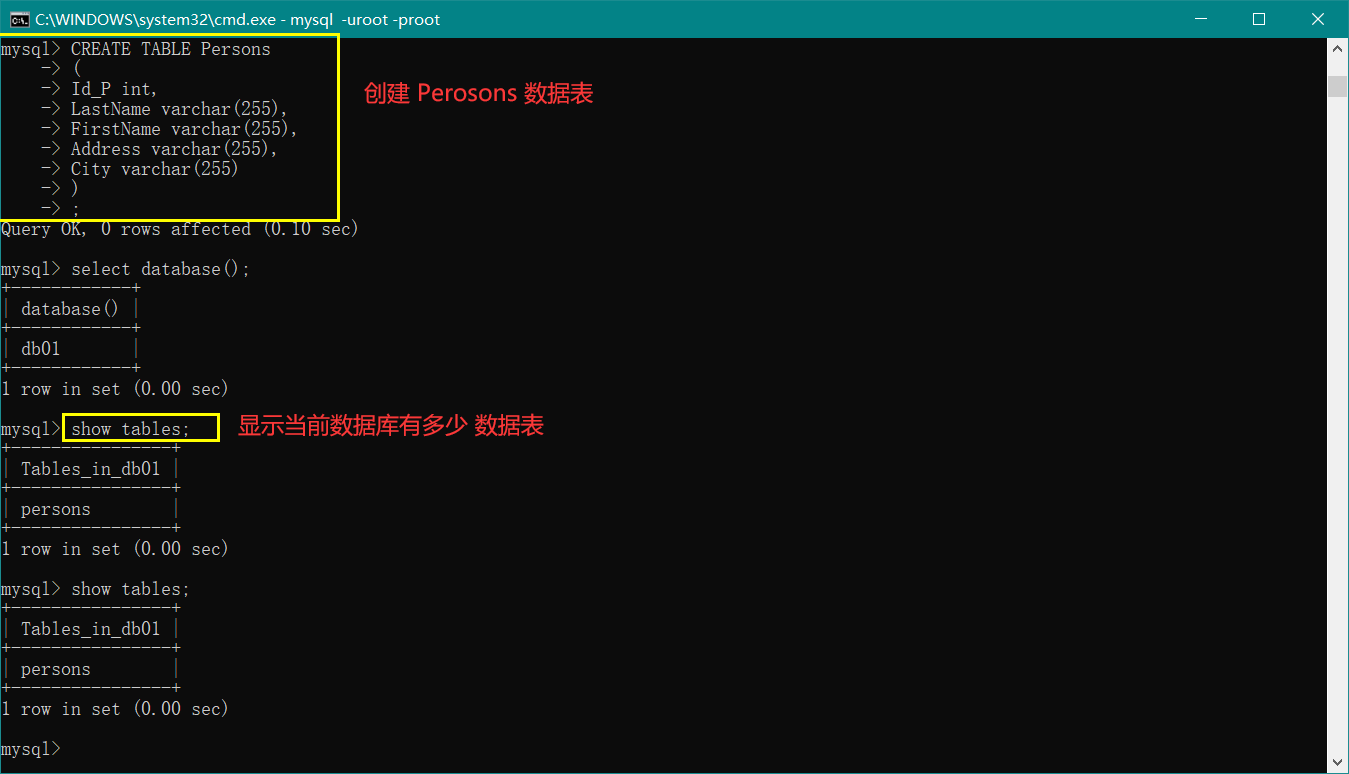
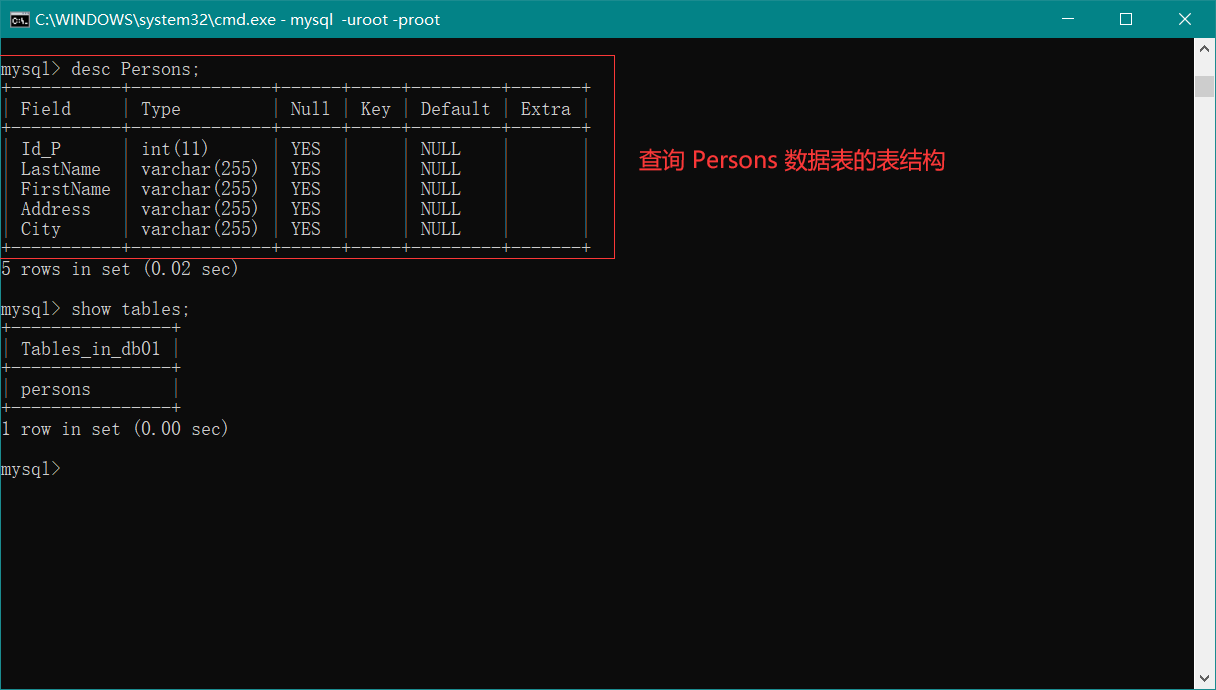
操作数据表的其他命令 就不再一个一个地演示了,详情看上方的
SQL 命令汇总自行练习。接下来介绍图形化界面工具 SQLyog。
图形化界面工具有时间再补充……DML-数据操作语言
DML 概念: 数据操作语言【DML】是 (Data Manipulation Language) 的缩写形式。用来对数据库中 表的数据进行增删改 。相关关键字: insert , delete , update 等。
1 | /* |
由于时间关系,具体的操作截图就不弄了,
命令模板和命令实际操作上述代码都有,参阅然后自行实操。
DQL-数据查询语言
DQL 概念: 数据查询语言【DQL】是 (Data Query Language) 的缩写形式。用来查询数据库中表的记录(数据)。相关关键字: select , where 等。
1 | # 基本语法介绍 |
接下来,我们使用上述基本语法实现各种查询骚操作。第一步: 创建一张表并插入数据,操作如下:
1 | -- 创建 student 表 |
第二步: 我们使用 SQLyog 图形化界面工具创建上述的 student 表 ,并插入数据和查询,如下图:
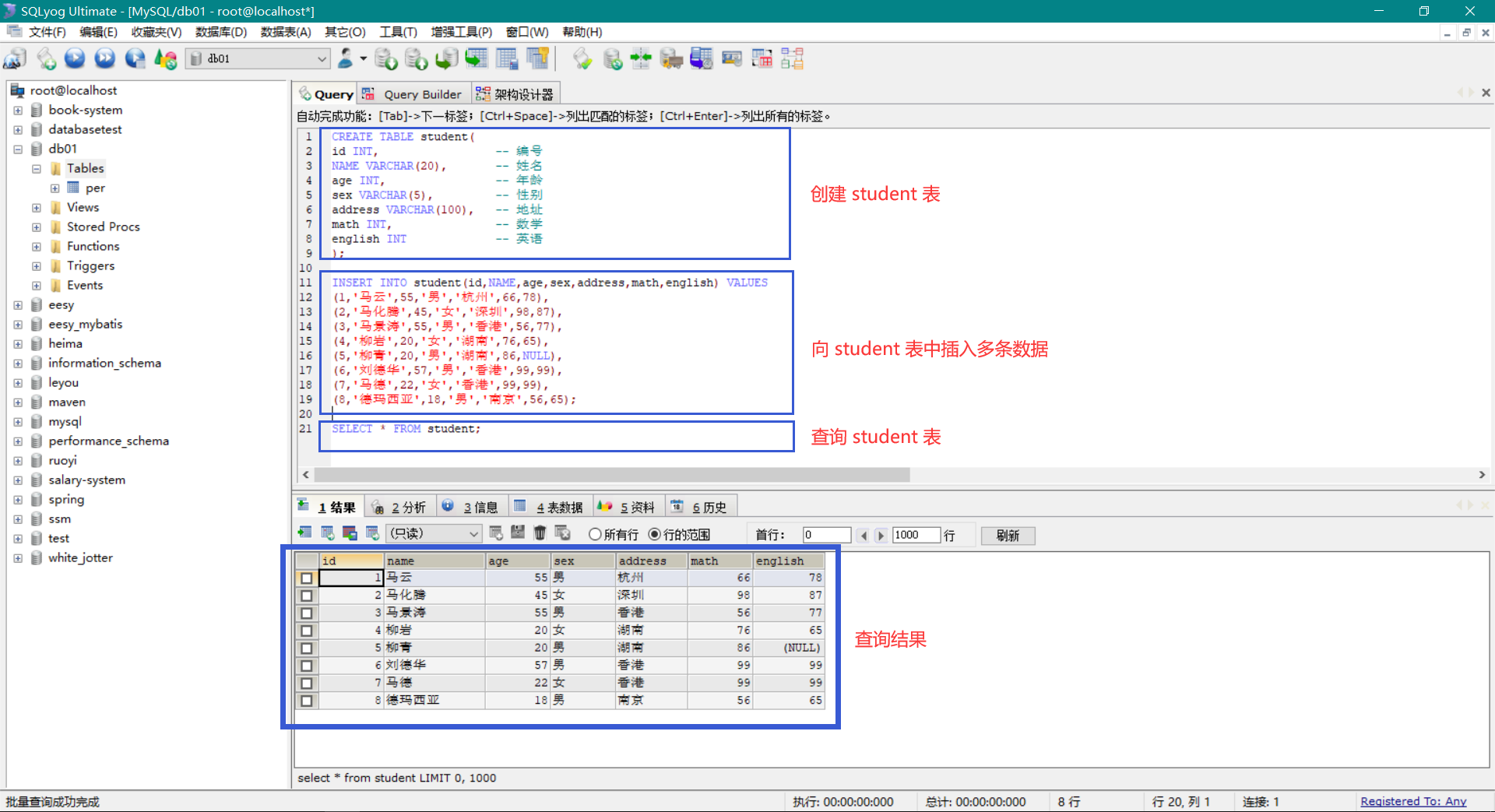
第三步: 开始操作。接下来的各种查询操作都是 基于 student 表 ,所以必须创建好,并且有数据,以下是 基础查询操作命令 如下:
1 | -- 基础查询操作 |
第四步: 上述基础查询操作命令自己去练习,时间紧张,就不截图了。接下来介绍 条件查询操作命令 ,如下:
1 | -- 条件查询操作,where 子句后跟条件 |
第五步: 上述条件查询操作命令自己去练习,时间紧张,就不截图了。接下来介绍 排序查询操作命令 ,如下:
1 | # 排序查询操作语法: order by 排序字段1 排序方式1 , 排序字段2 排序方式2... |
第六步: 接下来介绍 聚合函数操作命令 ,如下:
1 | # 聚合函数:将一列数据作为一个整体,进行纵向的计算。 |
第七步: 接下来介绍 分组查询操作命令 ,如下:
1 | # 分组查询语法: group by 分组字段; |
第八步: 接下来介绍 分页查询操作命令 ,如下:
1 | # 分页查询语法:limit 开始的索引,每页查询的条数; |
DCL-数据控制语言
DCL 概念: 数据控制语言【DCL】是 (Data Control Language) 的缩写形式。用来定义数据库的访问权限和安全级别,以及创建用户。相关关键字: GRANT , REVOKE 等。
1 | # 1、查询用户 |
用户权限管理 相关的操作如下:
1 | # 1、查询权限 |
重点来喽: 如果我们忘记了 MySQL 密码怎么办? 以下 骚操作 记好:
表的约束
约束概念及分类
约束概念: 对表中的数据进行限定,保证数据的 正确性 、有效性 和 完整性 。
约束命令汇总
第一个: 非空约束 命令汇总如下:
1 | # 非空约束:not null,加了这个约束的字段的值不能为 null,如下表的 name 字段 |
第二个: 唯一约束 命令汇总如下:
1 | # 唯一约束:unique,值不能重复 |
第三个: 主键约束 命令汇总如下:
1 | # 主键约束:primary key。 |
第四个: 外键约束 命令汇总如下:
1 | # 外键约束:foreign key , 让表于表产生关系,从而保证数据的正确性。 |
第五个: 外键约束_级联操作 命令汇总如下:
1 | # 由于 employee 表和 department 表有外键关联,所以当需要修改 department 表的 id 字段时会报错。 |
多表操作及关系
第一步: 一对多(多对一) 的实现关系,如下图:

第二步: 多对多 的实现关系,如下图:
第三步: 一对一(了解) 的实现关系,如下图:

三大范式
设计数据库时,需要遵循的一些规范,这些规范就叫范式。而要遵循后边的范式要求,必须先遵循前边的所有范式要求。
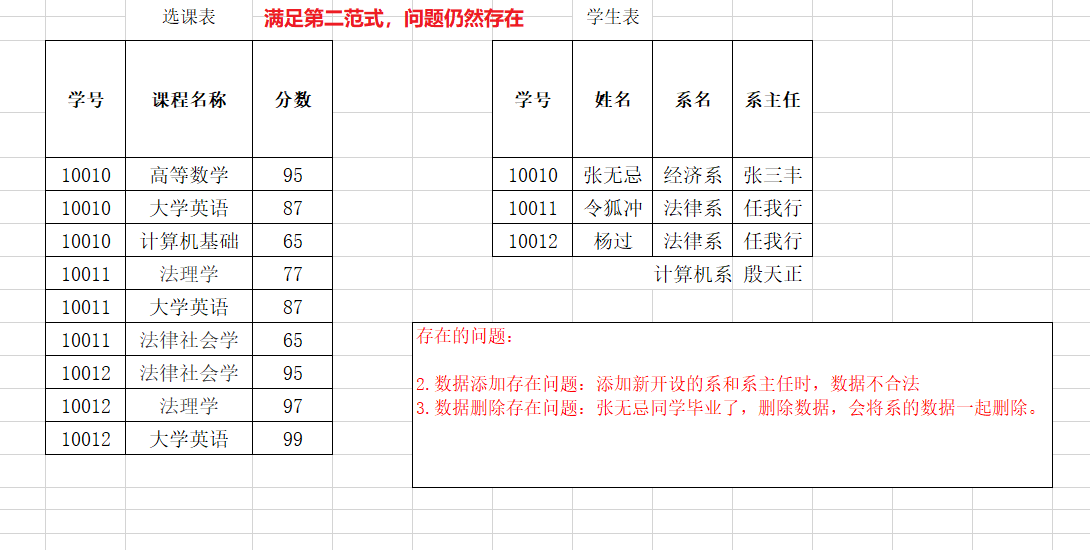
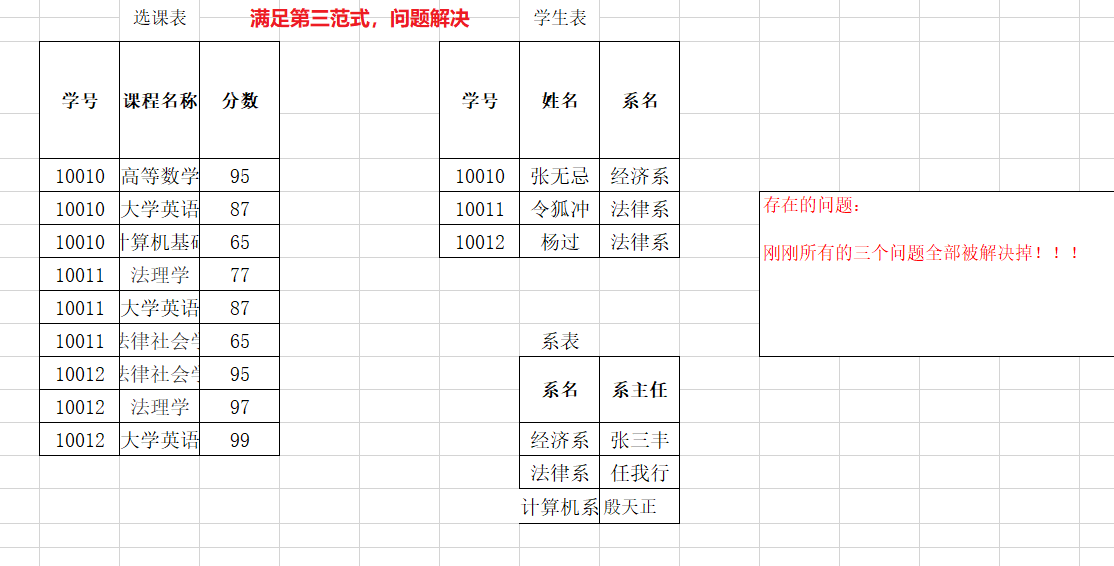
几个概念:
1. 函数依赖:A-->B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A
例如:学号-->姓名。 (学号,课程名称) --> 分数
2. 完全函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定需要依赖于A属性组中所有的属性值。
例如:(学号,课程名称) --> 分数
3. 部分函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定只需要依赖于A属性组中某一些值即可。
例如:(学号,课程名称) -- > 姓名
4. 传递函数依赖:A-->B, B -- >C . 如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称 C 传递函数依赖于A
例如:学号-->系名,系名-->系主任
5. 码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
例如:该表中码为:(学号,课程名称)
* 主属性:码属性组中的所有属性
* 非主属性:除过码属性组的属性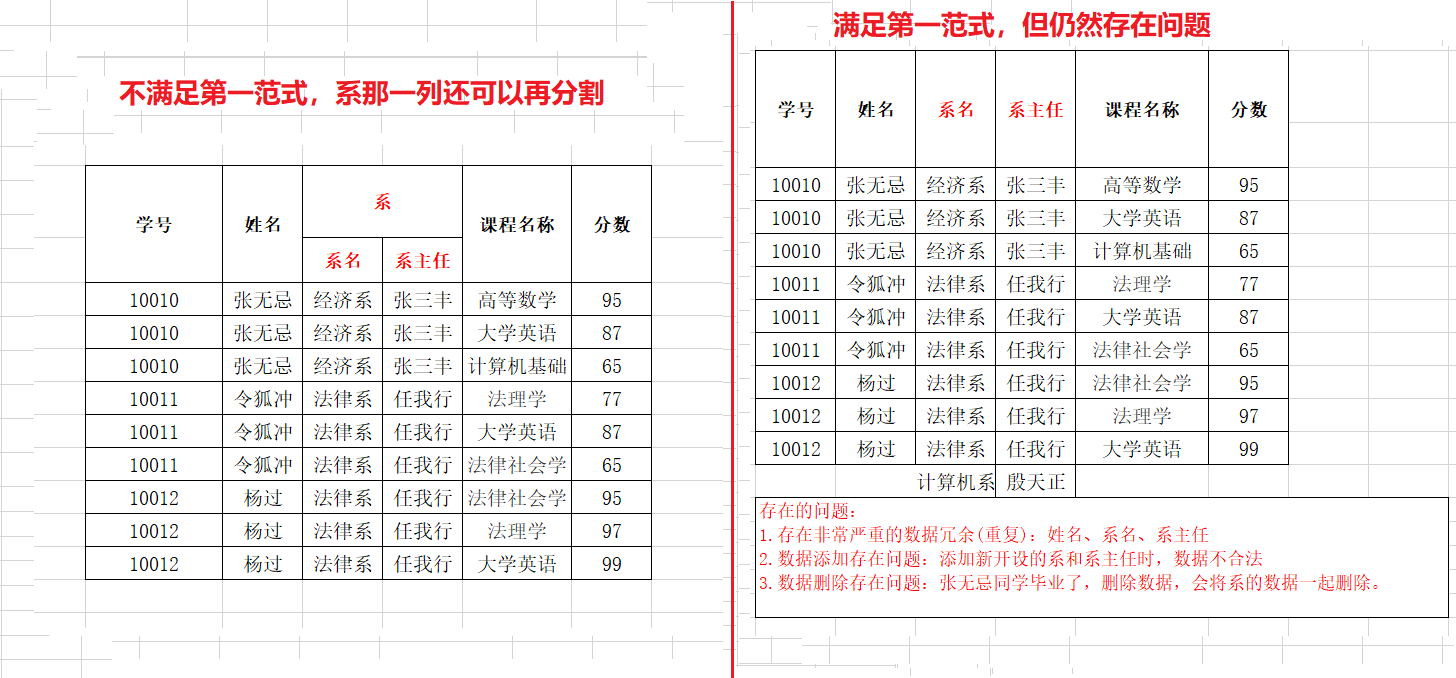
数据库的备份和还原
1 | # 命令行操作方式 |
SQL 高级
多表查询及分类
当我们进行多表查询时,返回结果是 笛卡尔积 。笛卡尔积存在很多无用的数据,需要消除他们,就需要用到下述三类查询。
前期准备 ,就是建立需要进行查询的表,并了解一些概念,如下:
1 | # 首先准备两张表,部门表和员工表 |
内连接查询
隐式内连接: 使用 where 条件 消除无用数据,如下:
1 |
|
显式内连接: 使用显式内连接来消除无用数据,如下:
1 | -- 显式内连接语法 |
外连接查询
左外连接:左外连接的相关介绍及语法如下:
1 | -- 左外连接语法:查询的是左表所有数据以及其交集部分。outer 可以省略 |
右外连接:右外连接的相关介绍及语法如下:
1 | -- 右外连接语法:查询的是右表所有数据以及其交集部分。 |
TIPS:左外连接和右外连接学一个就行了,都是一样的意思。
子查询
1 | # 子查询概念:查询中嵌套查询,称嵌套查询为子查询。 |
多表查询练习
第一步: 创建一个数据库,然后创建下列表:
1 | -- 部门表 |
第二步: 需求一和需求二分析查询,如下表:
1 | -- 1、查询所有员工信息。查询员工编号,员工姓名,工资,职务名称,职务描述 |
第三步: 需求三和需求四分析查询,如下表:
1 | -- 3、查询员工姓名,工资,工资等级 |
第四步: 需求五和需求六分析查询,如下表:
1 | -- 5、查询出部门编号、部门名称、部门位置、部门人数 |
事务
事务概念及相关操作
事务的概念: 如果一个包含 多个步骤 的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败。
代码举例:
1 | -- 创建 account 表 |
事务的两种提交方式
1 | # 事务提交的两种方式: |
事务的四大特征
事务的隔离级别
概念: 多个事务之间隔离的,相互独立的。但如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就能解决这些问题。
注意事项:隔离级别从小到大安全性越来越高,但是效率越来越低。
1 | # 数据库查询隔离级别: |
隔离级别演示如下:
1 | # CMD 同时打开两个 MySQL 窗口,同时进入相同数据库和相同表,并且开启事务 |
JDBC 相关知识
JDBC 基本概念
JDBC 概念: JDBC 是 Java DataBase Connectivity 的缩写形式,翻译成中文为 Java 数据库连接 ,即使用 Java 语言操作数据库。JDBC 本质: 其实是官方(sun 公司)定义的一套操作所有关系型数据库的规则,即 接口 。各个数据库厂商去实现这套接口,提供 数据库驱动 jar 包 。我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动 jar 包中的实现类。
快速入门
快速入门小案例,代码如下:
1 | /** |
JDBC 详解
第一个: DriverManager:驱动管理对象 ,它有如下两个功能:
1 | # DriverManager 功能一:注册驱动,告诉程序该使用哪一个数据库驱动 jar |
1 | # DriverManager 功能二:获取数据库连接,方法:static Connection getConnection(String url, String user, String password) |
第二个: Connection:数据库连接对象 ,它有如下两个功能:
1 | # Connection 的两个功能: |
第三个: Statement:执行 sql 的对象 ,介绍如下:
1 | # 1、执行 sql |
Statement:执行 sql 的对象 的练习,代码如下:
1 | public static void main(String[] args) { |
第四个: ResultSet:结果集对象,封装查询结果 ,介绍如下:
1 | # ResultSet:结果集对象,封装查询结果 |
ResultSet 结果集对象的一个练习 (只查询单条记录) ,代码如下:
1 | public static void main(String[] args) { |
ResultSet 结果集对象的一个练习 (查询所有记录) ,代码如下:
1 | public static void main(String[] args) { |
ResultSet 结果集对象的一个 小案例 ,把数据库表中的数据封装到 JavaBean 中,代码如下:
1 | /** |
上面定义好了一个实体类,与数据库相映射,现在就来编写具体的测试类,代码如下;
1 | /** |
JDBC 工具类
JDBC 工具类 小案例,代码如下:
1 | /** |
编写配置文件,放在 src 目录 下,文件内容如下:
1 | url=jdbc:mysql:///db01 |
编写 JDBC 工具类的演示类,代码如下:
1 |
|
JDBC 练习
JDBC 的一个登陆操作小案例,代码如下:
1 |
|
第五个: PreparedStatement:执行 sql 的对象 ,介绍如下:
1 | # PreparedStatement:执行 sql 的对象 |
JDBC 事务
1 | /** |
数据库连接池
当我们操作数据库时,我们每次都创建一个连接,然后操作完成之后释放这个连接。如此的频繁操作导致效率很低,因而连接池出现了,它解决了 资源浪费、效率低下 的问题。
连接池概念和优点
连接池概念: 连接池其实就是一个容器(集合),存放数据库连接的容器。当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器。草图如下:
连接池的实现
Java 提供了一个标准接口来实现连接池: javax.sql 包下的 DataSource 接口。我们不会去实现它,而是由数据库厂商去实现。
C3P0 连接池
C3P0 是一个开源的 JDBC 连接池 ,它实现了数据源与 JNDI 绑定,支持 JDBC3 规范和实现了 JDBC2 的标准扩展说明的 Connection 和 Statement 池的 DataSources 对象 。即将用于连接数据库的连接整合在一起形成一个随取随用的数据库连接池(Connection pool)。
C3P0 代码演示如下:
1 | <c3p0-config> |
1 | /** |
验证一下 c3p0-config.xml 中的各种参数,代码如下:
1 |
|
Druid 连接池
Druid 为阿里巴巴的数据源(数据库连接池),集合了 c3p0、dbcp、proxool 等连接池的优点,还加入了日志监控,有效的监控 DB 池连接和 SQL 的执行情况。Druid 的 DataSource 类 为:com.alibaba.druid.pool.DruidDataSource 。
Druid 代码演示如下:
1 | driverClassName=com.mysql.jdbc.Driver |
1 | /** |
封装一个工具类,方便以后的各种操作,工具类如下:
1 | /** |
工具类类写好了,是否好用呢?来测试一下吧。代码如下:
1 | /** |
到此为止,连接池的内容就结束了!
JDBC Template
JDBC Template 介绍
连接池虽然提高了效率,工具类也简化了一些操作,但是仍然觉得很麻烦。有木有更简单一点的操作呢?只关注 sql 本身,而不去管其他的东西?有,它就是 JDBC Template 。它是 Spring 框架对 JDBC 的简单封装,提供了一个 JDBCTemplate 对象简化 JDBC 的开发。
JDBC Template 入门程序
1 | /** |
JDBC Template 练习
定义一个 实体类 ,与数据库中的 emp 表 相对应,如下:
1 | import java.util.Date; |
编写测试类,代码如下:
1 | public class JdbcTemplate_Practice { |
数据库知识到此就结束了。以后还会写一些数据库性能优化的文章,继续加油吧!!!
问题解决
1、【使用可视化工具连接远程服务器数据库】client does not support authentication 解法
1 |
|
解决 Can’t connect to MySQL server (10060) 问题:如果连接不上远程服务器的 MySQL,可以去阿里云或者其他云服务器官网添加安全组规则,使服务器开发3306端口。或者是查看防火墙的状态,如果防火墙开启了,那么需要关闭。
